1. Meta AI的NLLB-200登上Nature
Meta AI在社交媒体X上宣传自家的大模型NLLB,全称为No Language Left Behind,这个AI模型能够翻译200种语言,包括资源匮乏的语言,更难得的是,NLLB模型可以免费提供给非商业用途。
这项研究刊登在了本周的Nature上,题为Scalling neural machine translations to 200 languages。

在全世界范围内,大约有7000种语言,有一半被认为面临灭绝,NLLB模型最大的价值在于,它提供了一种扩大资源匮乏型语言机器翻译规模的方法,这些资源匮乏的语言几乎没有可获取的数字资源。
2. 37项SOTA!全模态预训练范式MiCo
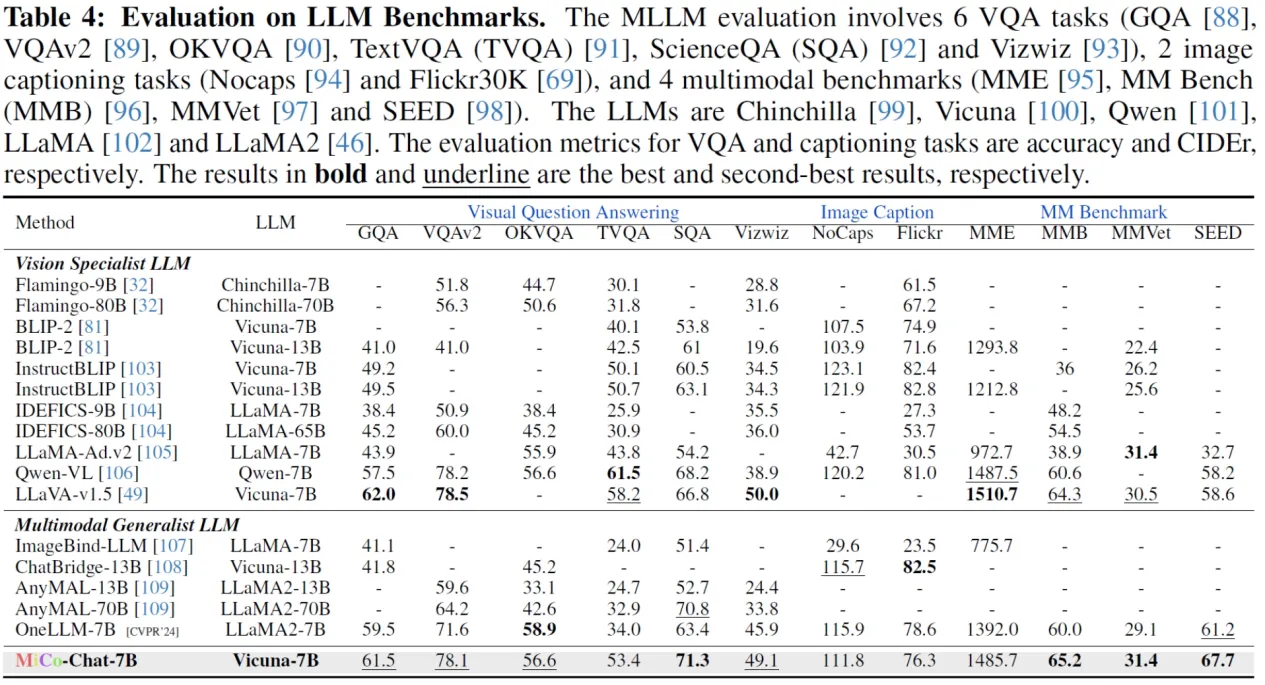
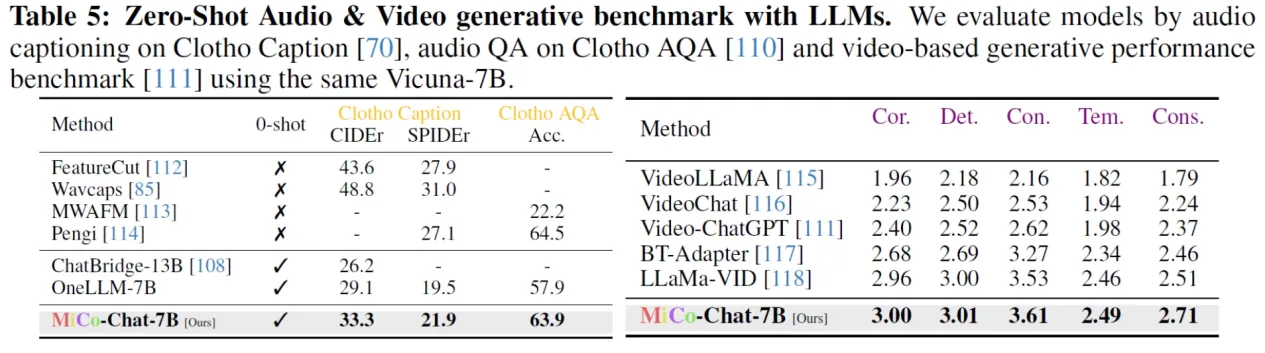
港中文、中科院等提出了一种大规模的全模态预训练范式,称为多模态上下文MiCo(Multimodal Context),它可以在预训练过程中引入更多的模态,数据量,模型参数。
在18种多模态大模型问答基准测试中,MiCo斩获10项SOTA
项目网站:https://invictus717.github.io/MiCo/
开源代码:https://github.com/invictus717/MiCo
Hugging Face模型:https://huggingface.co/Yiyuan/MiCo-ViT-g-14-omnimodal-300k-b64K
3. 北大快手攻克复杂视频生成难题
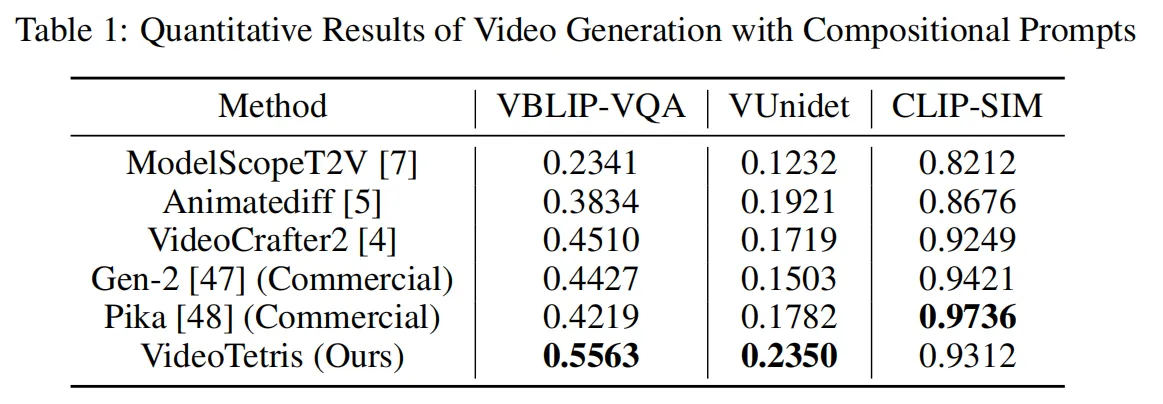
北大与快手联合提出新框架VideoTetris,就像拼俄罗斯方块一样,轻松组合生成高难度、指令超复杂的视频。在复杂视频生成任务中,超过了Pika,Gen-2等一众商用模型。

Videotetris首次定义组合视频生成,包括跟随复杂组合指令的视频生成和跟随递进的组合式多物体指令的长视频生成。经团队测试发现,几乎所有开源模型,包括商用模型在内都未能生成正确的视频。而Videotetris则表现不错。
另一方面,VideoTetris 框架使用了时空组合扩散方法,将一个提示词首先按照时间解构,为不同的视频帧指定好不同的提示信息。
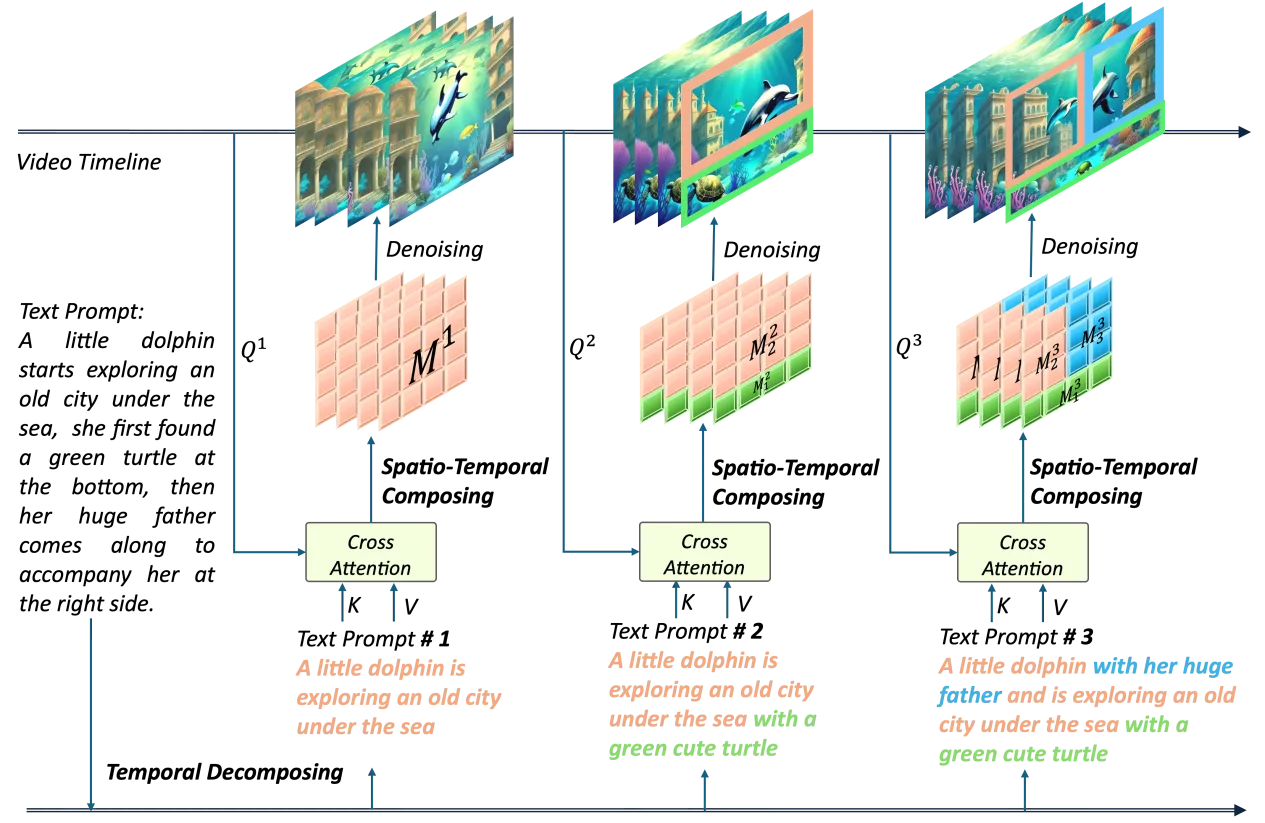
接着,在每一帧上进行空间维度的解构,将不同物体对应不同的视频区域。最后,通过时空交叉注意力进行组合,通过这个过程实现高效的组合指令生成。
为了生成更高质量的长视频,该团队还提出了一种增强的训练数据预处理方法。使得长视频生成更加动态稳定。
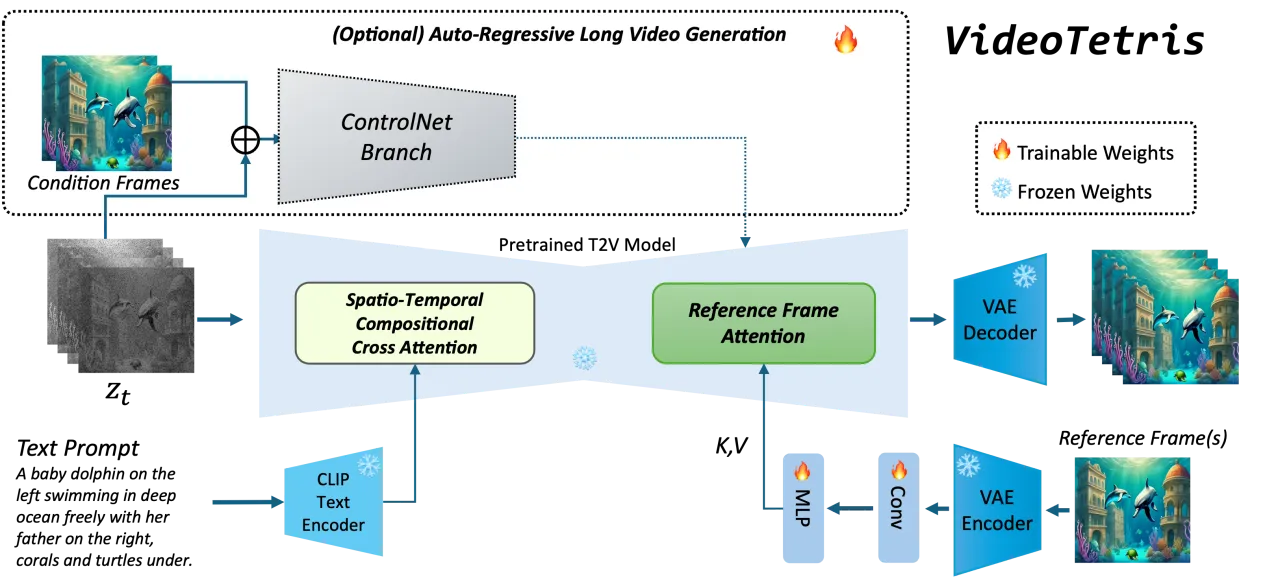
此外Videotetris还引入了一个参考帧注意力机制,使用原生VAE对之前的帧信息编码,区别于StreamingT2V,Vlogger,IPAdapter等使用CLIP 编码的方式,这样使得参考信息的表示空间和噪声完全一致,轻松获取更好的内容一致性。