软硬件环境
- Intel(R) Xeon(R) CPU E5-1607 v4 @ 3.10GHz
- ubuntu 18.04 64bit
- GTX 1070Ti 8G/32G
- darknet git version
- cuda 8.0
- opencv 3.4.3
- miniconda with python 3.7.1
前言
先说说我这的具体情况,需要检测的对象是老鼠,手上已经有的数据是图片以及图片中老鼠的坐标位置(x,y, width, height)。要做的就是利用这些信息,通过YOLOv3训练出老鼠的检测器,应用到实际的场景中去。
VOC数据集的组织结构
检测模型的训练依照VOC数据集的训练方法进行。首先来看看VOC数据集训练文件夹的目录结构
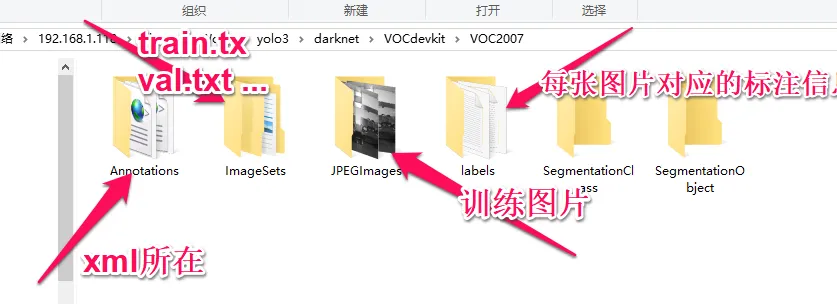
其中,
Annotations: 这里存放所有的xml文件, 它的文件格式如下
<annotation>
<folder>VOC2007</folder>
<filename>1548339112.jpg</filename>
<size>
<width>1920</width>
<height>1080</height>
<depth>3</depth>
</size>
<object>
<name>mouse</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>522</xmin>
<ymin>629</ymin>
<xmax>588</xmax>
<ymax>699</ymax>
</bndbox>
</object>
</annotation>size标签下的width和height是指图片的大小,object下的xmin、ymin、xmax、ymax则是物体的坐标信息,如果有多个物体,object标签对应会有多个。
ImageSets: 关注Main文件夹下的train.txt、trainval.txt、val.txt和test.txt,train.txt必须,其它可以不要,它们的格式都是一样的,记录的是图片的文件名,不带扩展名,如下
1548339040
1548339112
1548339126
1548339138
1548339675
1548339682
1548339690
1548339698
1548339706
1548339712
1548339864
1548339870
1548339874
1548339880
1548339887
1548340230-
JPEGImages: 训练图片的存储位置 -
labels: 这个文件夹下的内容可以通过脚本生成,一张图片对应一个txt文件,它的内容如下
0 0.2921875 0.6217592592592592 0.021875 0.05092592592592593老鼠检测模型的训练步骤
既然已经有了图片已及老鼠对应的坐标信息,所以手动标注这一步就可以省略掉。整体的训练应该分成以下几步
- 根据坐标信息生成
xml标注文件,一张图片对应一个xml文件 - 分别生成包含图片文件名信息的
train.txt、val.txt、trainval.txt,test.txt - 生成
labels文件夹下的txt文件 - 修改配置文件
data/voc.names、cfg/voc.data和cfg/yolov3-voc.cfg - 开始训练
训练过程
生成Annotations下的xml文件
由于手头已经有了具体的坐标信息了,我把它们存储到了mysql数据库中,然后利用相应的图片及坐标信息生成对应的xml文件,代码存放在https://code.xugaoxiang.com/longjingtech/YOLOv3XmlGenerator
生成ImageSets/Main下的txt文件
以train.txt为例,其它的都一样,要处理之前,可以把训练的、校验的、测试的图片分别放在不同的文件夹下,这样可以大大方便脚本处理,具体情形需要你自行修改
# -*- coding: utf-8 -*-
"""
@author: Xu Gaoxiang
@license: Apache V2
@email: xugx.ai@gmail.com
@site: https://www.xugaoxiang.com
@software: PyCharm
@file: mainTxtGenerator.py
@time: 2019/1/25 17:57
"""
import os
with open('train.txt', 'a') as f:
source_folder = 'VOC2007/JPEGImages'
file_list = os.listdir(source_folder)
for file_obj in file_list:
print('file: {}'.format(file_obj))
file_name, file_extend = os.path.splitext(file_obj)
f.write(file_name + '\n')
生成label下txt文件
darknet工程下scripts目录下有个voc_label.py文件,我们通过修改它来实现,需要将它移动到darknet下运行
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["mouse"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2007_train.txt 2007_val.txt > train.txt")
除此以外,在darknet根下生成了2007_train.txt等文件,内容是图片的完整路径
修改配置文件
data/voc.names存放的是检测对象的名称,如我这里的mouse,需要检测几个就写几个
cfg/voc.data内容如下,因为我只检测老鼠,所以classes=1,其它路径自行修改
classes= 1
train = /home/longjing/Work/yolo3/darknet/2007_train.txt
valid = /home/longjing/Work/yolo3/darknet/2007_val.txt
names = data/voc.names
backup = backup_mousecfg/yolov3-voc.cfg 主要修改classes,根据自己的硬件情况调整batch和subdivisions的值
开始训练
使用如下命令进行训练
cd darknet
wget https://pjreddie.com/media/files/darknet53.conv.74
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74在这里我碰到了darknet: ./src/parser.c:312: parse_yolo: Assertion l.outputs == params.inputs failed. 的错误,解决的方法是修改cfg/yolov3-voc.cfg中的filters,将其值改为18,这个参考值来自网络,计算方法3*(classes+5)
小结
一般情况下,都是拿到包含某种待检测对象的图片,然后需要根据图片进行训练得到检测模型。这样的话,就需要手动标注,得到相应的坐标信息,生成xml文件,GUI标注工具labelImg就是干这样的事情。我上面的xml生成器其实就是干的labelImg的活。

