软硬件环境
- ubuntu 18.04 64bit
- GTX 1070Ti
- anaconda with python 3.7
- pytorch 1.6
- cuda 10.1
前言
前文 基于YOLOv5和DeepSort的目标跟踪 介绍过利用 YOLOv5 和 DeepSort 来实现目标的检测及跟踪。不过原项目的模型中只包含常见的人,对于其它目标就无能为力了,本文就来训练自己的跟踪器来实现特定目标的跟踪。
至于 YOLOv5 检测模型的训练,参考前面的博文 YOLOv5模型训练。
Market 1501数据集
Market-1501 数据集是在清华大学校园中采集,在夏天拍摄,于2015年构建并公开。它包括由6个摄像头(其中5个高清摄像头和1个低分辨率摄像头)拍摄到的1501个行人、32668个检测到的行人矩形框。每个行人至少有2个摄像头捕捉到,并且在一个摄像头中可能具有多张图像。训练集有751人,包含12936张图像,平均每个人有17.2张训练数据;测试集有750人,包含19732张图像,平均每个人有26.3张测试数据。3368张查询图像的行人检测矩形框是人工绘制的,而 gallery 中的行人检测矩形框则是使用 DPM 检测器检测得到的。
数据集目录结构
Market-1501-v15.09.15
├── bounding_box_test
├── bounding_box_train
├── gt_bbox
├── gt_query
├── query
└── readme.txt包含四个文件夹
bounding_box_test: 用于测试bounding_box_train: 用于训练query: 有750个身份。我们为每个摄像机随机选择一个查询图像gt_query: 包含实际标注。对于每个查询,相关图像被标记为“好”或“垃圾”。“垃圾”对搜索准确性没有任何影响。“垃圾”图像还包括与query相同的相机中的图像gt_bbox: 手绘边框,主要用于判断DPM边界框是否良好
图片命名规则
以 0001_c1s1_000151_01.jpg 为例
- 0001表示每个人的标签编号,从0001到1501,共有1501个人
c1表示第一个摄像头(c是camera),共有6个摄像头s1表示第一个录像片段(s是sequence),每个摄像机都有多个录像片段- 000151表示
c1s1的第000151帧图片,视频帧率fps为25 - 01表示
c1s1_001051这一帧上的第1个检测框,由于采用DPM自动检测器,每一帧上的行人可能会有多个,相应的标注框也会有多个。00则表示手工标注框
数据集下载地址:
链接:https://pan.baidu.com/s/1i9aiZx-EC3fjhn3uWTKZjw
提取码:up8x
Market到底怎么组织
原始的数据集结构是这样的
Market-1501-v15.09.15
├── bounding_box_test
├── bounding_box_train
├── gt_bbox
├── gt_query
├── query
└── readme.txt而 bounding_box_train 和 bounding_box_test 目录下就是具体的图片文件了,这里面并没有体现 id。正确的做法是:将某个 id (也就是某个人)的图片放在一个文件夹内,且以该 id 作为文件夹的名称。如将 bounding_box_train 下所有以 0002 开头的图片文件存放在文件夹 0002 下
bounding_box_test 下的图片处理也是一样,test 中有个 id 是-1,嗯?真没弄懂,但不影响训练。
针对上述的操作,写了个简单的脚本
import os
import sys
import shutil
if __name__ == '__main__':
root = os.path.join(sys.argv[1], 'dataset')
os.mkdir(root)
train_dir = os.path.join(root, 'train')
test_dir = os.path.join(root, 'test')
os.mkdir(train_dir)
os.mkdir(test_dir)
# 处理train
for file in os.listdir(os.path.join(sys.argv[1], 'bounding_box_train')):
print(file)
id = file.split('_')[0]
if not os.path.exists(os.path.join(train_dir, id)):
os.mkdir(os.path.join(train_dir, id))
else:
shutil.copy(os.path.join(sys.argv[1], 'bounding_box_train', file), os.path.join(train_dir, id))
# 处理test
for file in os.listdir(os.path.join(sys.argv[1], 'bounding_box_test')):
id = file.split('_')[0]
if not os.path.exists(os.path.join(test_dir, id)):
os.mkdir(os.path.join(test_dir, id))
else:
shutil.copy(os.path.join(sys.argv[1], 'bounding_box_test', file), os.path.join(test_dir, id))使用方法
python test.py Market-1501-v15.09.15脚本执行结束后,会在 Market-1501-v15.09.15 下生成文件夹 dataset,文件结构是这样的
dataset/
├── train
├── 0002
├── 0007
├── 0010
├── 0011
├── 0012
├── 0020
├── 0022
├── test
├── 0000
├── 0001
├── 0003
├── 0004
├── 0005
├── 0006
├── 0008
├── 0009这样就生成了一份可直接训练的数据集,而原有的也不会被破坏。
deepsort模型训练
依赖环境就不说了,参考前文
git clone --recurse-submodules https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch.git
cd Yolov5_DeepSort_Pytorch/deep_sort/deep_sort/deep接下来将数据集 Market 拷贝到 Yolov5_DeepSort_Pytorch/deep_sort/deep_sort/deep 下然后解压,数据集存放的位置是随意的,可以通过参数指定。
最后,需要改个地方,编辑 model.py,将
def __init__(self, num_classes=751 ,reid=False):改成
def __init__(self, num_classes=752 ,reid=False):然后就可以开始训练了
python train.py --data-dir Market-1501-v15.09.15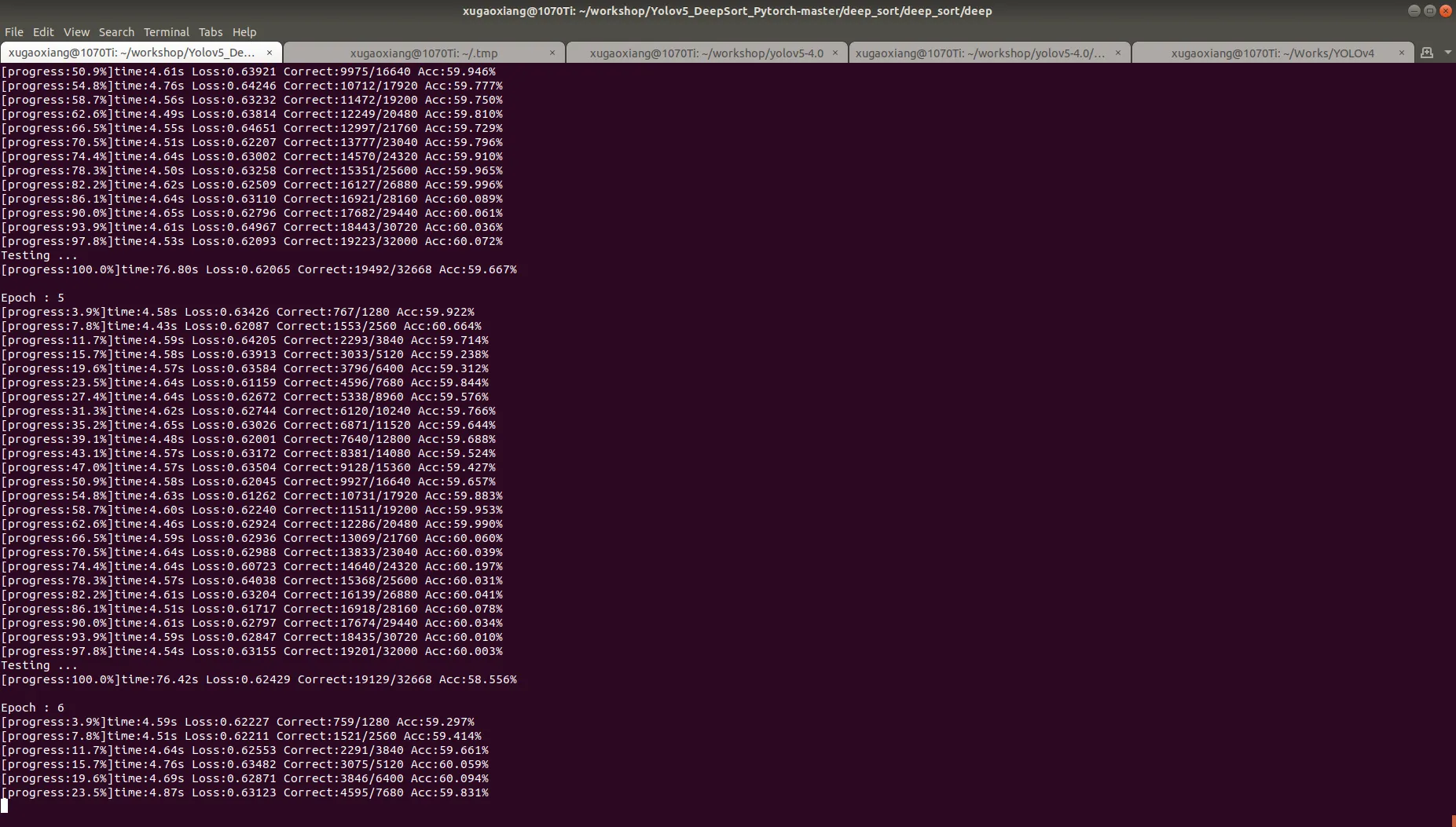
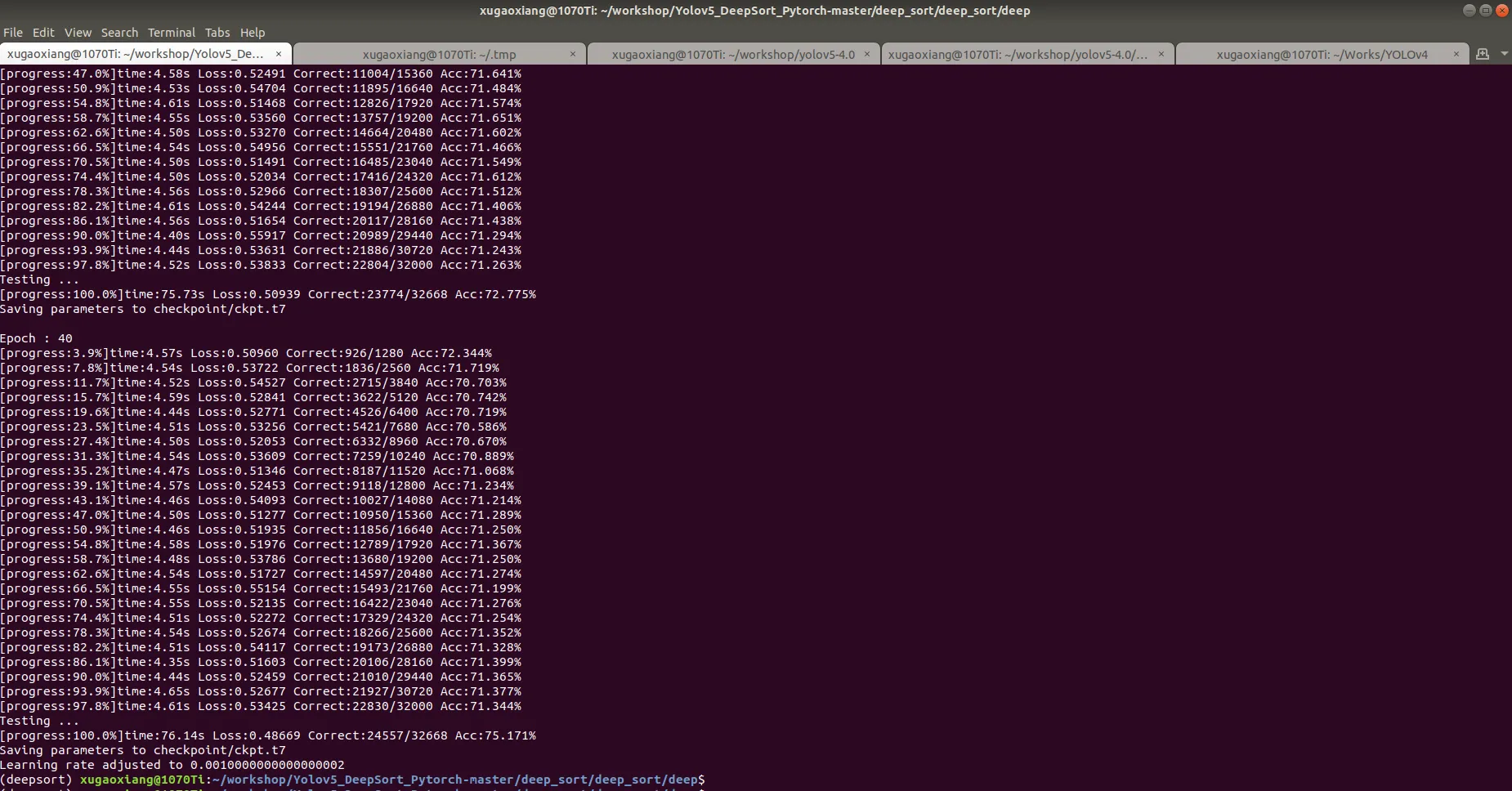
训练结束后,会在 checkpoint 下生成模型文件 ckpt.t7,找个视频,测试一下
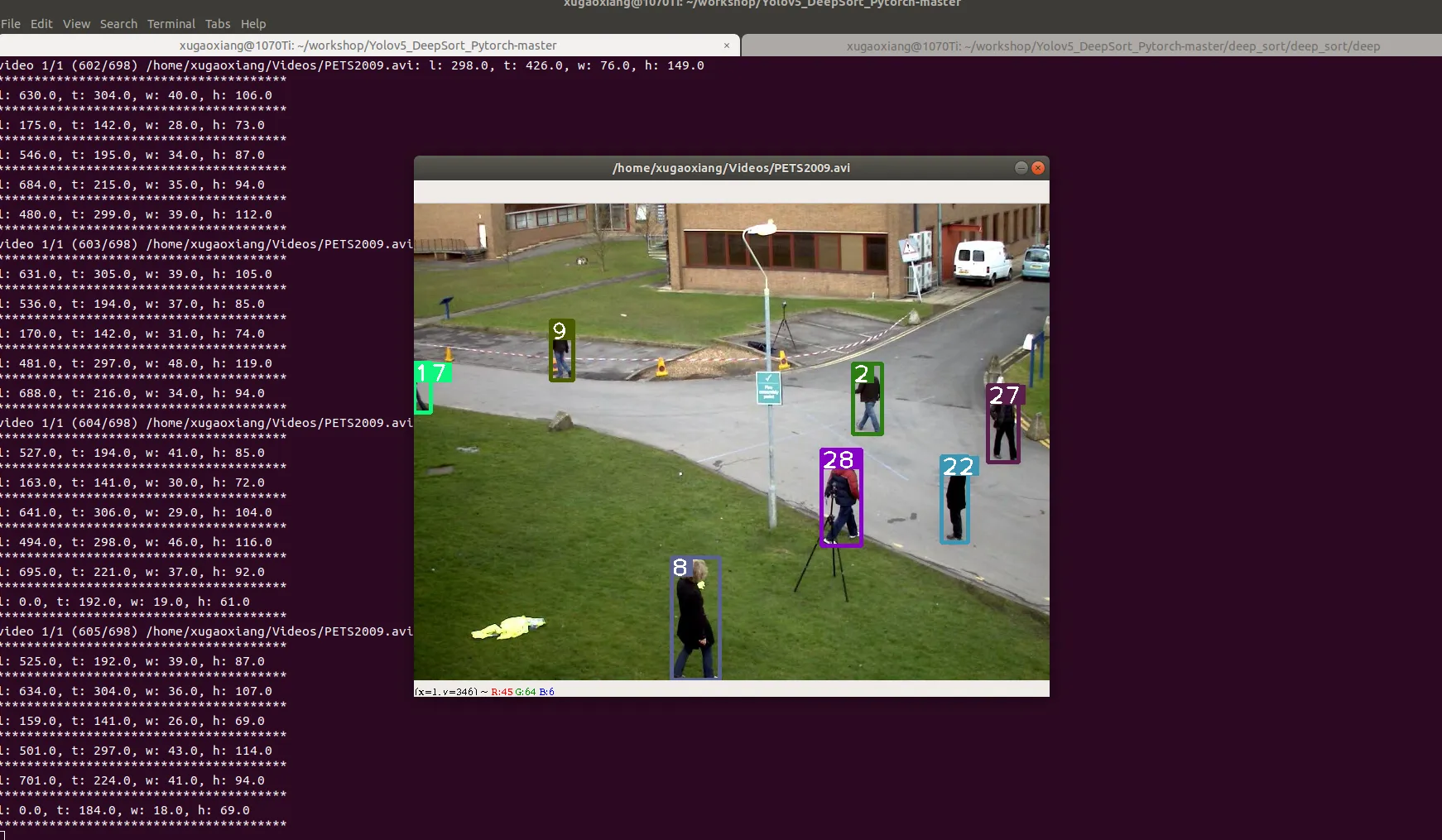
num_classes含义
这里解释下 num_classes 的含义,根据原工程 https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch 中 train.py 的代码
trainloader = torch.utils.data.DataLoader(
torchvision.datasets.ImageFolder(train_dir, transform=transform_train),
batch_size=64,shuffle=True
)
testloader = torch.utils.data.DataLoader(
torchvision.datasets.ImageFolder(test_dir, transform=transform_test),
batch_size=64,shuffle=True
)
num_classes = max(len(trainloader.dataset.classes), len(testloader.dataset.classes))可以看到,num_classes 是 train 和 test 集合中类型(也就是总 id 数)数目较大者的值,在 Market 1501 数据集中,train 中有751个,test 中有752(包括了一个id号为-1)个,因此,num_classes 就是752。
因此,在训练数据集的时候只需要修改 model.py,将 num_classes 改成752,train.py 无需修改。
备注
最后,再说一句,工程 https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch 中 deepsort 跟踪部分参考的是 https://github.com/ZQPei/deep_sort_pytorch,但是做了部分修改。前面训练都是基于 Yolov5_DeepSort 的。








