前言
AI 和高性能计算(HPC)的需求不断增长,单 GPU 的性能越来越捉襟见肘,因此需要在多 GPU 之间实现无缝连接,以便它们可以作为一个巨大的加速器相互协作。虽然已经存在 PCIe 标准,但带宽有限,因此通常会产生瓶颈。为构建功能强大的端到端计算平台,我们需要速度更快、扩展性更强的互联方式。
NVLink
NVIDIA NVLink 是世界首项高速 GPU 互连技术,与传统的 PCIe 系统解决方案相比,它能为多 GPU 系统提供更快速的替代方案。NVLink 技术通过连接多块 NVIDIA 显卡,能够实现显存和性能扩展,从而满足更大计算工作负载的需求。
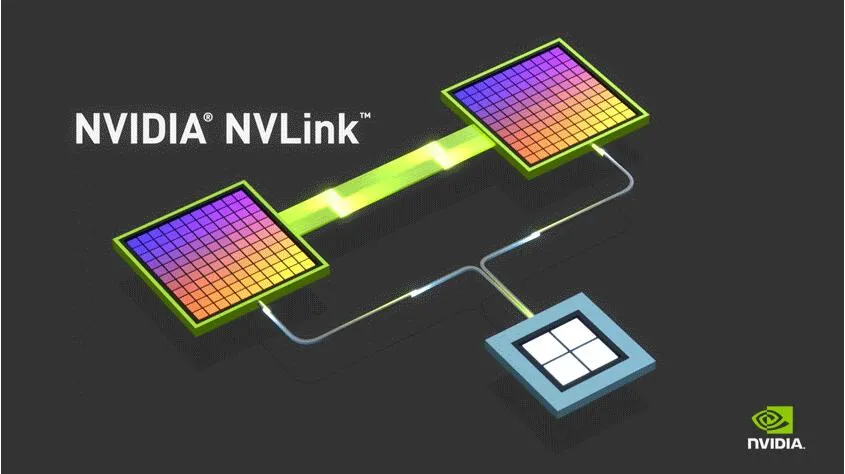
其实早在2014年的 GTC 大会上就提出 NVLink 技术,直到2016年,P100 发布,这是搭载 NVLink 的第一款产品,单个 GPU 具有 160 GB/s 的带宽,相当于 PCIe 3代带宽的5倍。在 GTC 2017上发布的 V100 搭载了 NVLink 2.0,更是将 GPU 带宽提升到了 300 G/s,差不多是 PCIe 3代的10倍。再到后来发布的 A100,集成了第三代的 NVLink,其单个 NVIDIA A100 Tensor 核心 GPU 支持多达12个 NVLink 连接,总带宽为 600 G/s,几乎是 PCIe Gen 4 带宽的10倍。目前 NVLink 已经进入第4代,达到了900 G/s。
目前已知的 NVLink 分为两种,第一种是以桥接器的形式实现 NVLink 高速互联技术

另一种是在主板上集成 NVLink 接口,并通过安装 NVLink 接口来实现高速互联

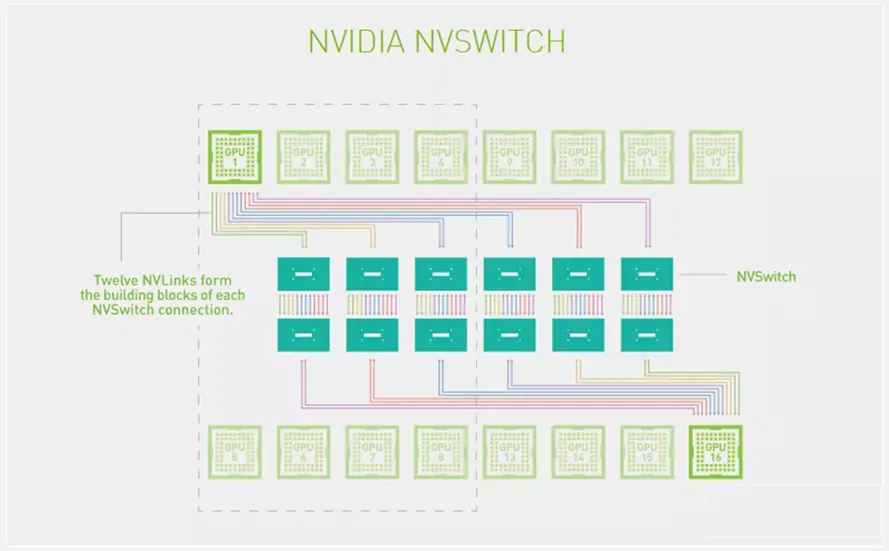
NVSwitch
说到 NVLink,就不得不提一下 NVSwitch
NVSwitch 是一种由 NVIDIA 开发的高性能互连交换机,主要用于构建数据中心和超级计算机中的大规模 GPU 集群。它的设计旨在提供高带宽、低延迟的通信通道,以支持大规模并行计算和深度学习工作负载。
NVSwitch 采用了多级交换架构,每个级别中包含了多个交换芯片。这种多级结构可以扩展系统规模,实现支持数千个 GPU 的互连。NVSwitch 的拓扑结构类似于非阻塞的完全连接网络,每个 GPU 可以直接与其他 GPU 进行通信,而不会出现瓶颈或冲突。