软硬件环境
- ubuntu 18.04 64bit
- CUDA 10.1
- chineseocr_lite
- anaconda with python 3.7
- pytorch
视频看这里
此处是youtube的播放链接,需要科学上网。喜欢我的视频,请记得订阅我的频道,打开旁边的小铃铛,点赞并分享,感谢您的支持。
简介
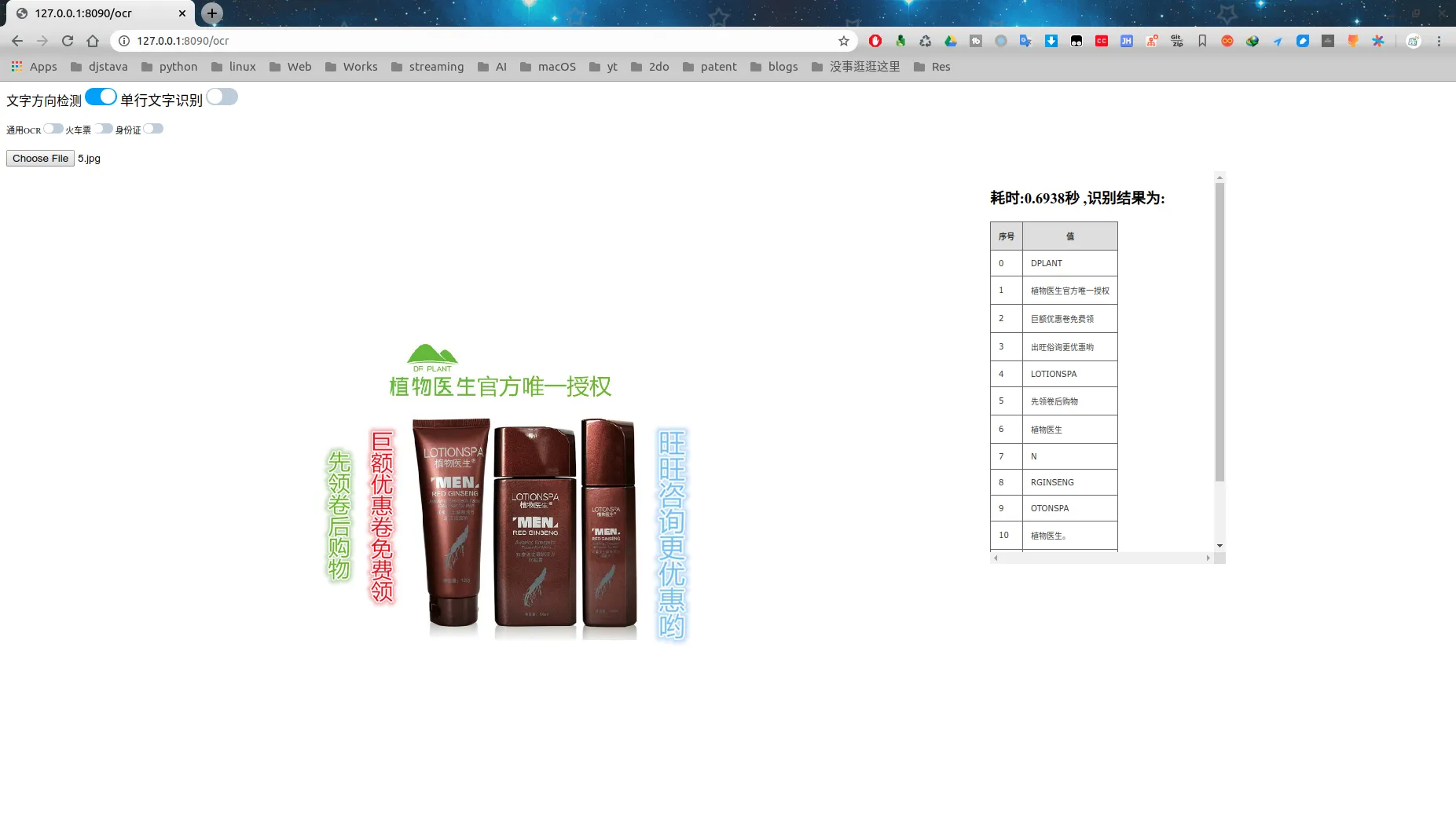
chineseocr_lite是一个开源项目,使用了c++和python开发语言,用来实现中文的文字识别,支持竖排文字识别、繁体识别,总模型只有17M(很小就是了),同时支持CPU和GPU,项目中集成了web环境,部署起来也非常方便。
基本安装及使用
从官方网站下载源码,然后我们使用conda创建一个新的python虚拟环境,激活虚拟环境后开始安装chineseocr_lite,相应的命令如下
git clone https://github.com/ouyanghuiyu/chineseocr_lite.git
cd chinesesocr_lite
conda create -n ocr python=3.7
conda activate ocr
pip install torch torchvision
pip install -r requirements.txt
pip install -U web.py
cd psenet/pse/
rm pse.so
make
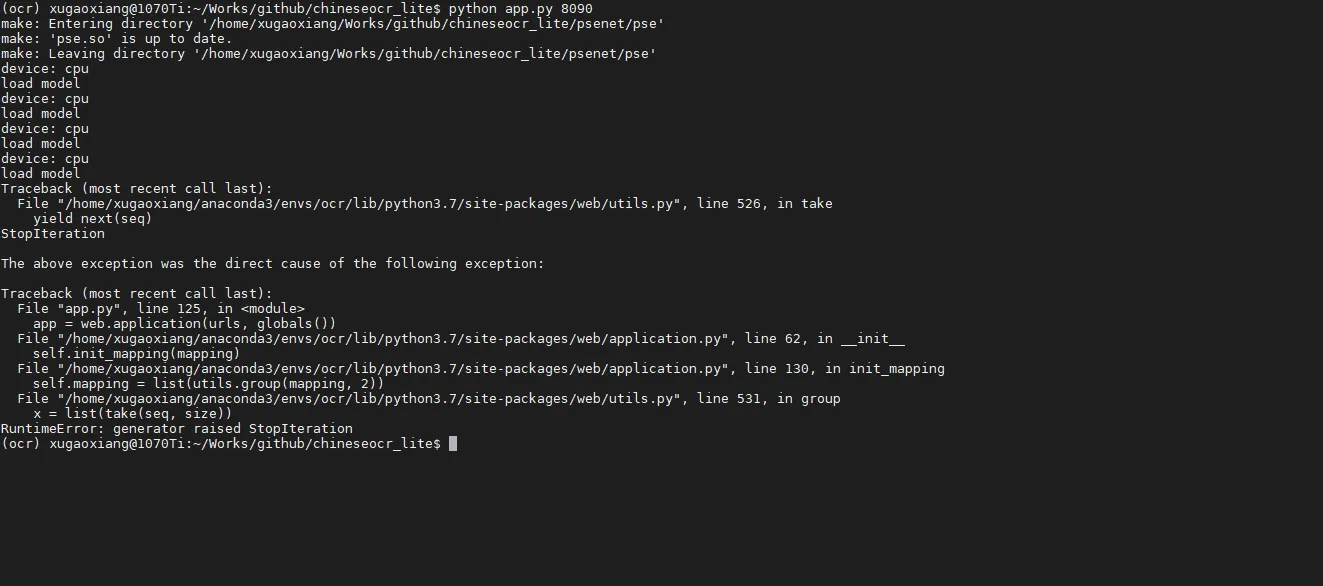
python app.py 8090这里需要注意下,requirements.txt中指定的web.py版本在运行的时候会报错,升级后就好了
至此,项目就已经安装好了,我们在浏览器中输入http://127.0.0.1:8090/ocr
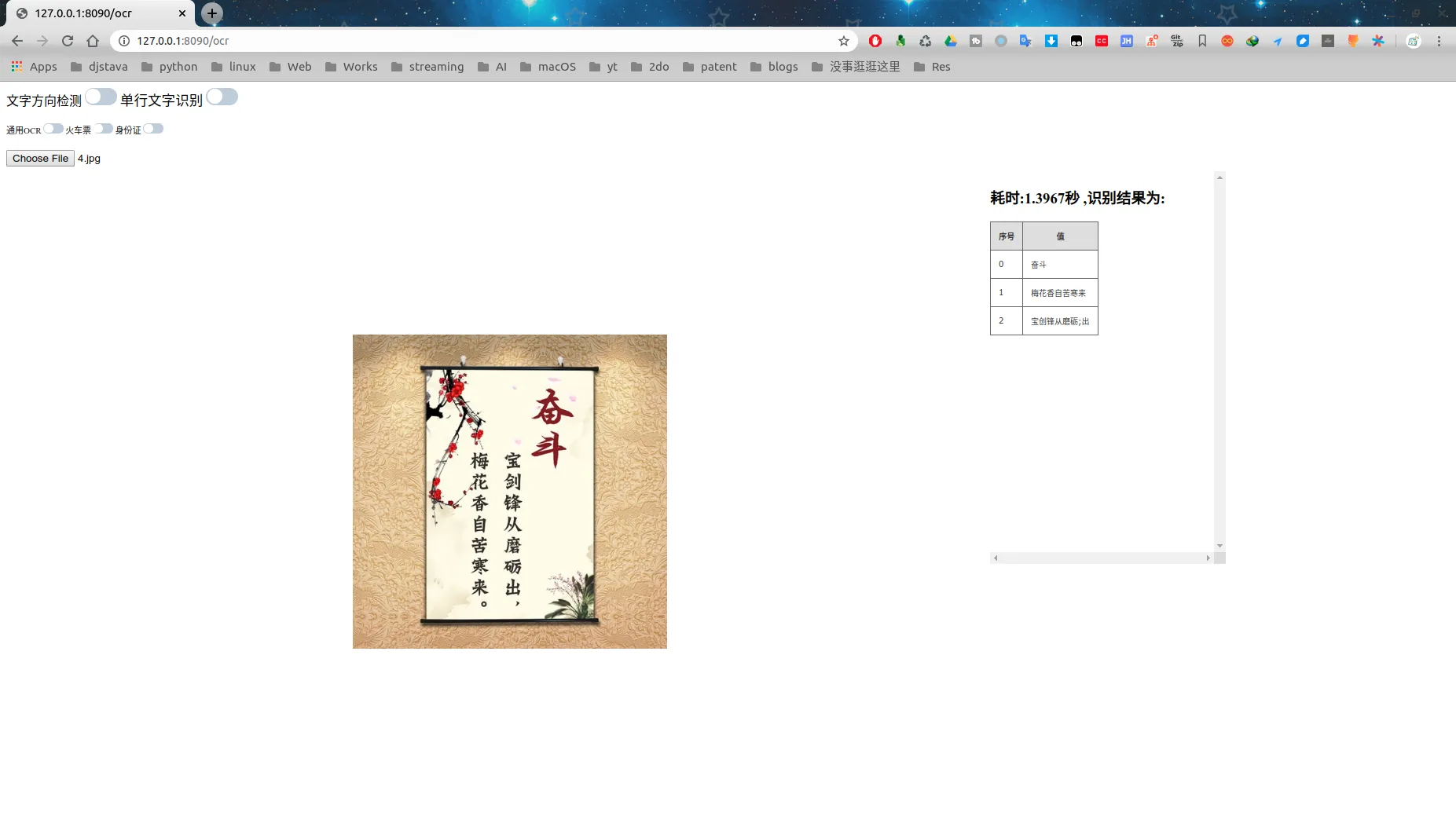
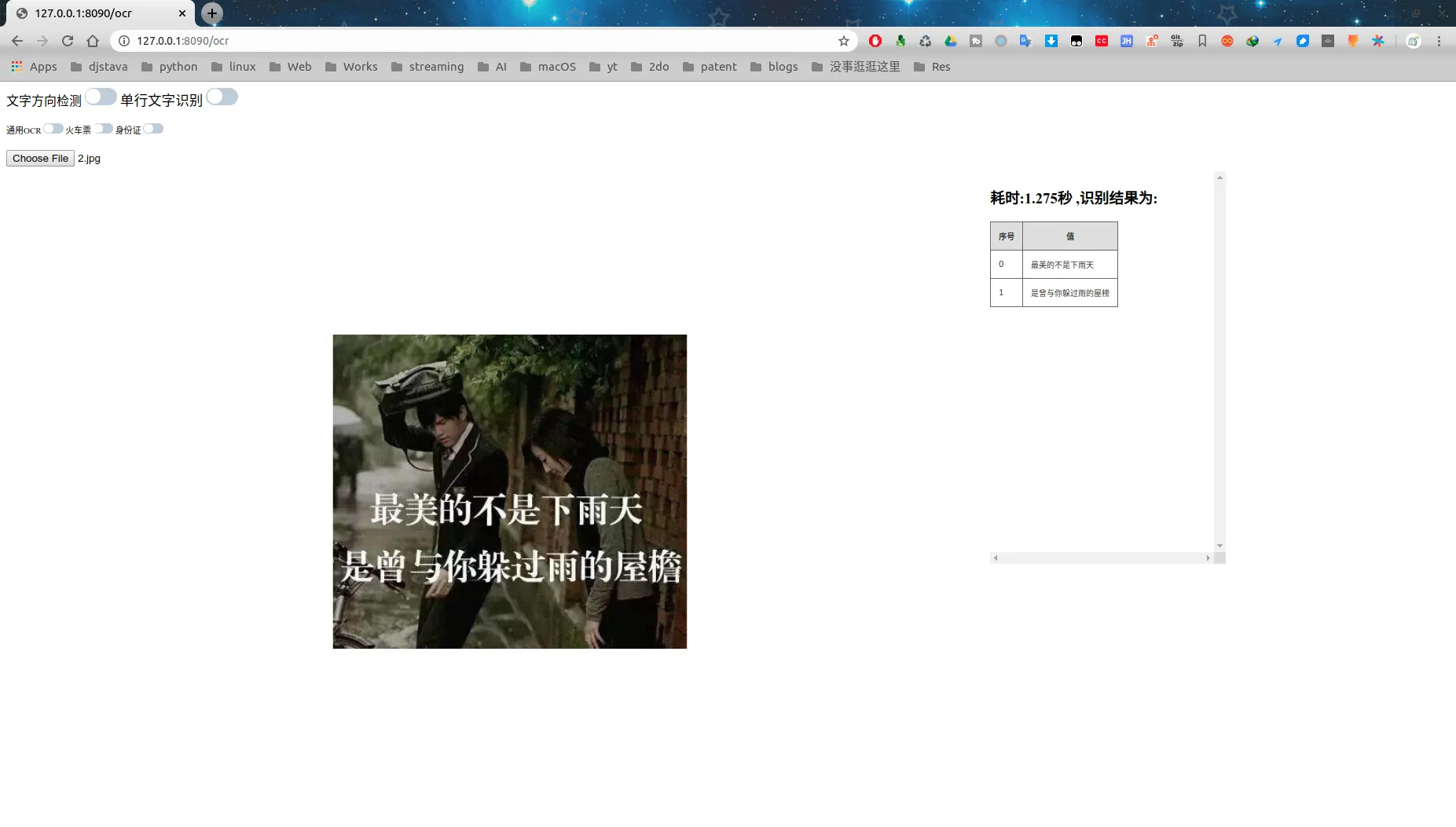
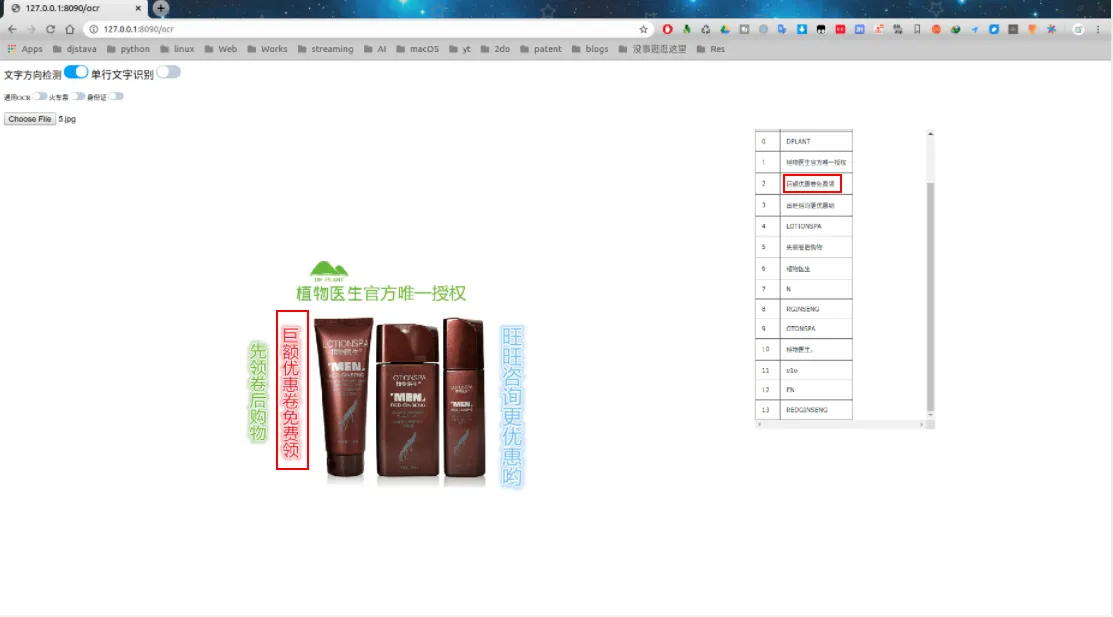
可以看到,对竖排文字也是基本可以识别出来的
使用GPU加速
来到pytorch的网站,https://pytorch.org/get-started/locally/,根据自己的环境进行选择,最后网站会出相应的安装命令,这点还是非常赞的
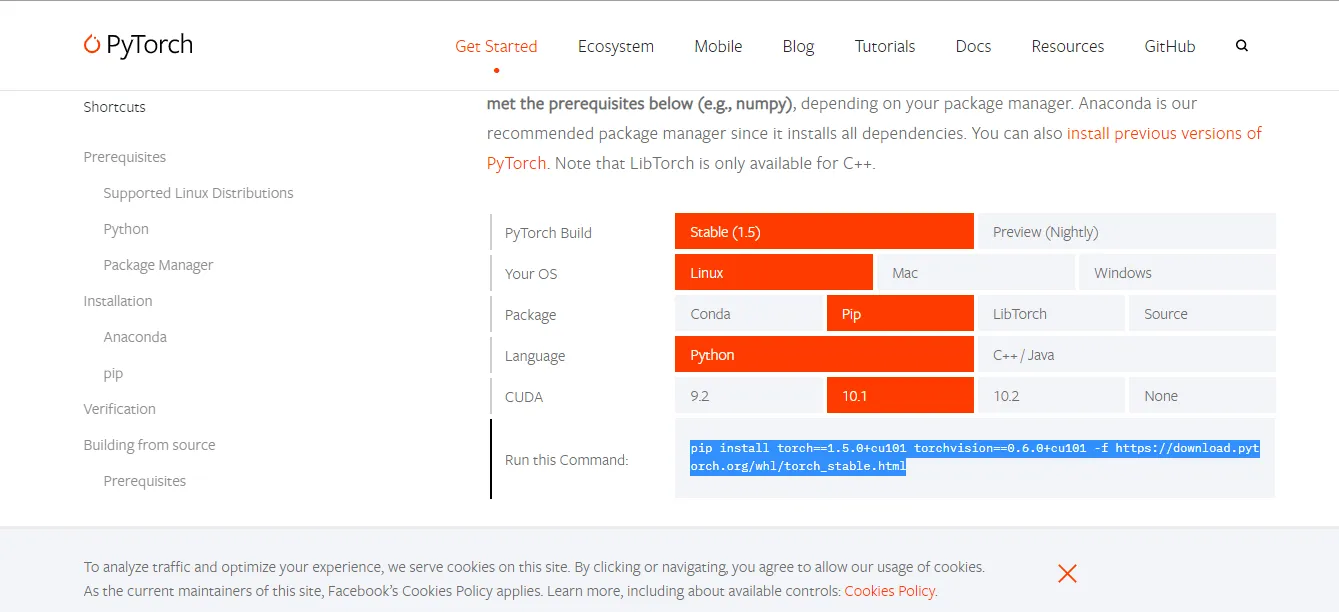
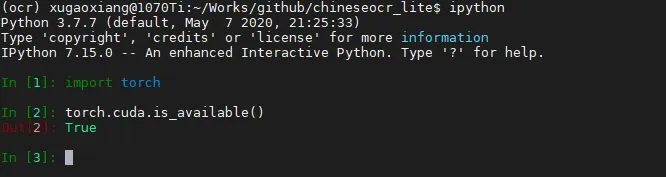
pip install torch==1.5.0+cu101 torchvision==0.6.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html安装好了以后,我们来到ipython来验证一下
重新启动web服务,device那块的输出,如果看到的是cuda而不是cpu,那就说明已经可以使用gpu了
(ocr) xugaoxiang@1070Ti:~/Works/github/chineseocr_lite$ python app.py 8090
make: Entering directory '/home/xugaoxiang/Works/github/chineseocr_lite/psenet/pse'
make: 'pse.so' is up to date.
make: Leaving directory '/home/xugaoxiang/Works/github/chineseocr_lite/psenet/pse'
device: cuda:0
load model
device: cuda:0
load model
device: cuda:0
load model
device: cuda:0
load model
http://0.0.0.0:8090/经过测试,同样的图片,gpu的识别花费时间只有cpu的1/3,效果还是不错的