环境
- windows 11
- python 3.9
前言
Muggle OCR 是一个高效本地 OCR 模块,旨在通过简单的几步设置提供强大的文本识别功能,无论是在处理印刷文本还是解析验证码,都能让用户在工作中畅通无阻。Muggle OCR 易于安装和使用,支持双模型,识别快速准确。
实操
首先下载源码
# 克隆代买
git clone https://github.com/litongjava/muggle_ocr.git
cd muggle_ocr
# 安装依赖
pip install -r requirements.txt
# 安装muggle ocr
python setup.py install
# 安装其它依赖
pip install absl-py ml-dtypes wrapt gast astunparse opt_einsum这里需要注意的是 python 版本需要3.8以上
安装完毕后,我们再来看看如何使用?看下面的示例
import time
# 1. 导入包
import muggle_ocr
"""
使用预置模型,预置模型包含了[ModelType.OCR, ModelType.Captcha] 两种
其中 ModelType.OCR 用于识别普通印刷文本, ModelType.Captcha 用于识别4-6位简单英数验证码
"""
# 打开印刷文本图片
with open(r"test1.png", "rb") as f:
ocr_bytes = f.read()
# 打开验证码图片
with open(r"test2.png", "rb") as f:
captcha_bytes = f.read()
# 2. 初始化;model_type 可选: [ModelType.OCR, ModelType.Captcha]
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.OCR)
# ModelType.Captcha 可识别光学印刷文本
for i in range(5):
st = time.time()
# 3. 调用预测函数
text = sdk.predict(image_bytes=ocr_bytes)
print('test1 text={}, time={}'.format(text, time.time() - st))
# ModelType.Captcha 可识别4-6位验证码
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.Captcha)
for i in range(5):
st = time.time()
# 3. 调用预测函数
text = sdk.predict(image_bytes=captcha_bytes)
print('test2 text={}, time={}'.format(text, time.time() - st))
"""
使用自定义模型
支持基于 https://github.com/kerlomz/captcha_trainer 框架训练的模型
训练完成后,进入导出编译模型的[out]路径下, 把[graph]路径下的pb模型和[model]下的yaml配置文件放到同一路径下。
将 conf_path 参数指定为 yaml配置文件 的绝对或项目相对路径即可,其他步骤一致,如下示例:
ocr.yaml和ocr.pb文件从源码包中拷贝过来
"""
with open(r"test2.png", "rb") as f:
b = f.read()
sdk = muggle_ocr.SDK(conf_path="./ocr.yaml")
st = time.time()
text = sdk.predict(image_bytes=b)
print('test3 text={}, time={}'.format(text, time.time() - st))
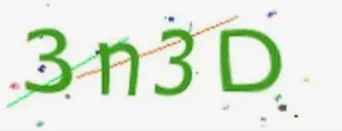
使用上述图片测试,执行代码可以得到
MuggleOCR Session [ocr] Loaded.
test1 text=曹文轩教授作序推荐, time=0.012343645095825195
test1 text=曹文轩教授作序推荐, time=0.008872270584106445
test1 text=曹文轩教授作序推荐, time=0.0076770782470703125
test1 text=曹文轩教授作序推荐, time=0.00856161117553711
test1 text=曹文轩教授作序推荐, time=0.007288694381713867
MuggleOCR Session [captcha] Loaded.
test2 text=3n3d, time=0.013895511627197266
test2 text=3n3d, time=0.008069753646850586
test2 text=3n3d, time=0.007512807846069336
test2 text=3n3d, time=0.007458209991455078
test2 text=3n3d, time=0.007974863052368164
MuggleOCR Session [ocr] Loaded.
test3 text=3n3D, time=0.010023832321166992示例中分别使用模型 ModelType.OCR 和 ModelType.Captcha 对不同类型的图片进行了文字识别,前者针对印刷文本,后者针图片验证码。第三个示例使用了配置文件 yaml 初始化模型,若指定 conf_path 参数则优先使用自定义模型。需要注意的是,muggle ocr 仅支持单行文本识别,如有多行识别需求可以考虑 earyocr 或者 umi-ocr。
