环境
- python 3.8
- pytorch 1.7 + cu110
- yolov5 6.1
- opencv 4.5.5
前言
在 yolov5 的 C++ 部署方案中,opencv 应该是最能被想到的一种,从 3.3 版本后,opencv 就加入了 dnn 这个模块,有了这个模块,很多的机器学习项目就可以通过它来实现部署了,下面我们就来看看具体的实现步骤。
yolov5
由于 opencv 无法直接读取 yolov5 中的 pt 模型文件,因此,需要将原来的 pt 文件转换成 opencv 能直接读取的 onnx 模型文件
使用目前最新的版本 v6.1,https://github.com/ultralytics/yolov5/releases/tag/v6.1,解压后,进入源码目录,下载对应的模型文件,这里使用 yolov5s.pt 为例,地址:https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
接下来使用源码中的转换脚本 export.py,将 pt 文件转成 onnx 格式
python export.py --weights yolov5s.pt --include onnx完成后就可以在当前目录下生成了 yolov5s.onnx 文件
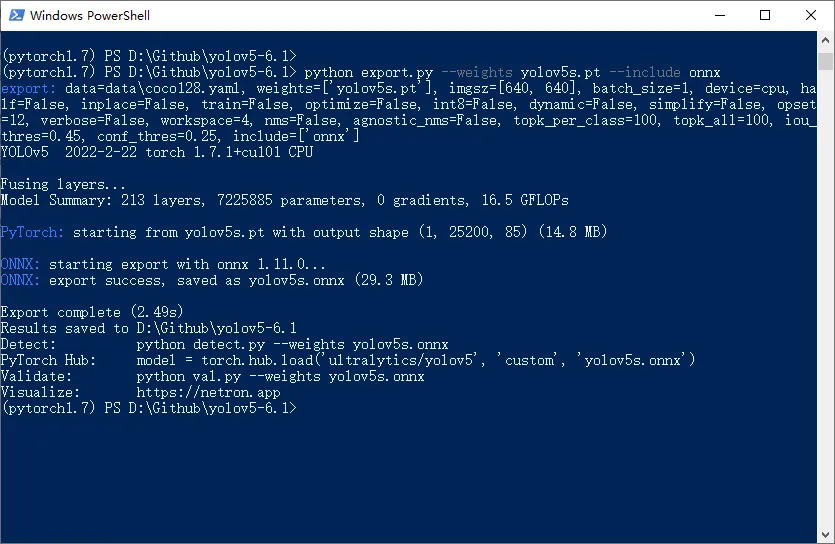
cmake
来到官网,https://cmake.org/download/,下载后,傻瓜式安装,然后,将其也加入到系统环境变量中
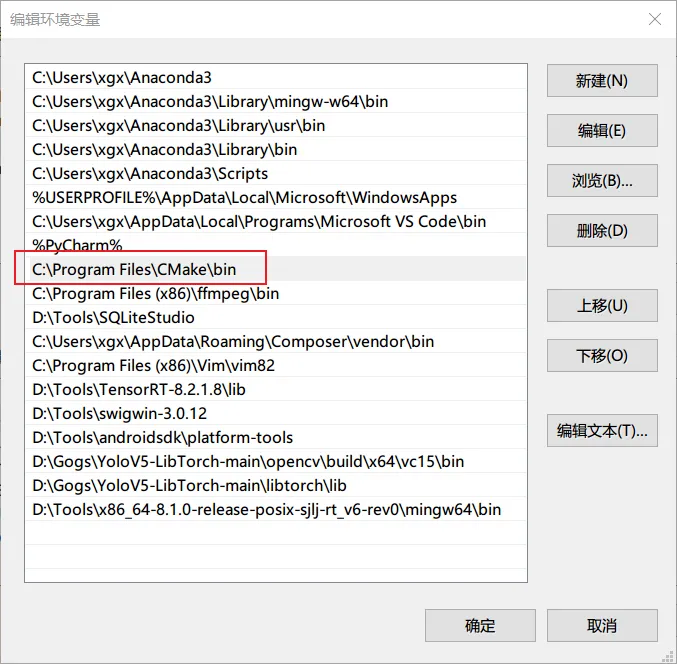
opencv
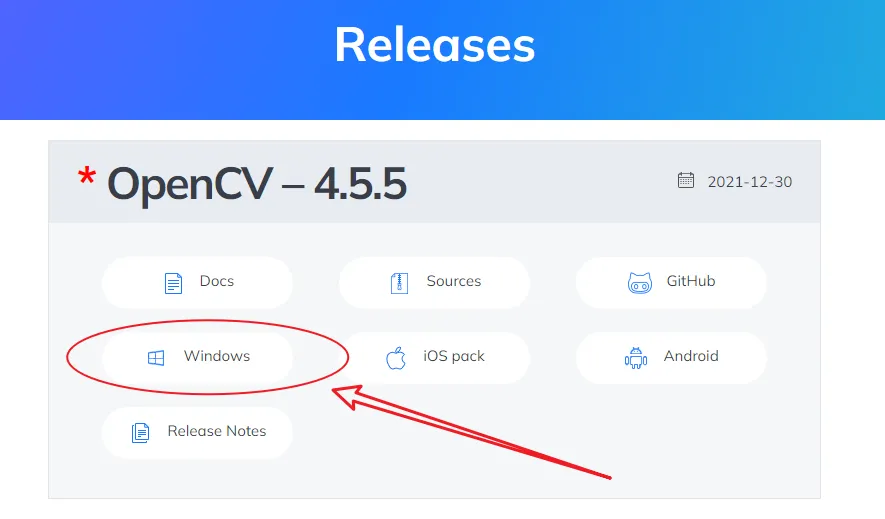
接下来,我们配置一下 opencv 的环境,来到官网 https://opencv.org/releases/,下载 windows 对应的版本,现在最新的版本是 4.5.5
下载完成后解压
然后新增一个环境变量 OpenCV_DIR,对应的值就是解压后的文件夹下的 build 目录,如下
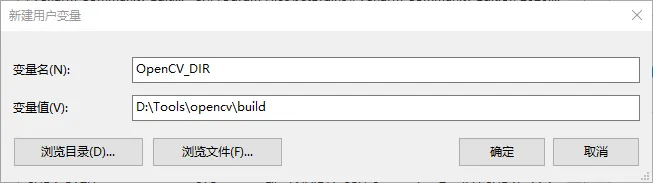
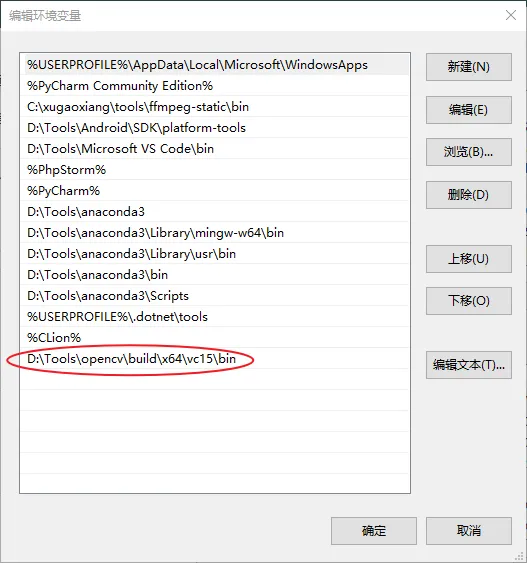
修改系统环境变量 Path,将 opencv 包中的 build\x64\vc\15\bin 添加进去
开始部署
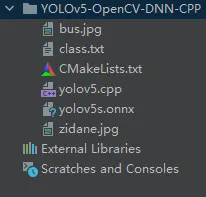
我们创建一个 C++ 项目,包含了源码文件 yolov5.cpp、CMakeLists.txt、目标名称文本文件 class.txt、yolov5s.onnx 和若干测试图片
CMakeLists.txt 定义了编译的规则
cmake_minimum_required(VERSION 3.20)
set(CMAKE_CXX_STANDARD 11)
project(yolov5dnn)
find_package(OpenCV REQUIRED)
add_executable(yolov5dnn yolov5.cpp)
include_directories(${OpenCV_INCLUDE_DIRS})
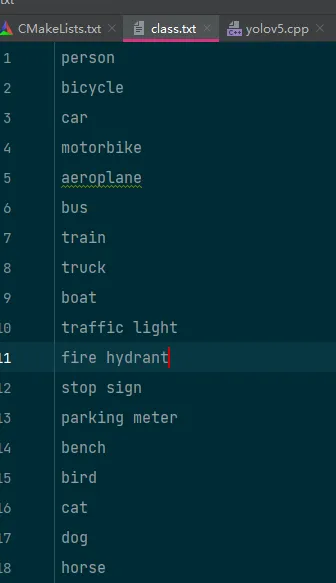
target_link_libraries(yolov5dnn ${OpenCV_LIBS} ${CMAKE_THREAD_LIBS_INIT})class.txt 是待检测的目标,默认模型是 coco 的80个目标
最后来看源码文件 yolov5.cpp
#include <opencv2/opencv.hpp>
#include <fstream>
using namespace cv;
using namespace std;
using namespace cv::dnn;
// 常量
const float INPUT_WIDTH = 640.0;
const float INPUT_HEIGHT = 640.0;
const float SCORE_THRESHOLD = 0.5;
const float NMS_THRESHOLD = 0.45;
const float CONFIDENCE_THRESHOLD = 0.45;
// 显示相关
const float FONT_SCALE = 0.7;
const int FONT_FACE = FONT_HERSHEY_SIMPLEX;
const int THICKNESS = 1;
Scalar BLACK = Scalar(0,0,0);
Scalar BLUE = Scalar(255, 178, 50);
Scalar YELLOW = Scalar(0, 255, 255);
Scalar RED = Scalar(0,0,255);
// 画框函数
void draw_label(Mat& input_image, string label, int left, int top)
{
int baseLine;
Size label_size = getTextSize(label, FONT_FACE, FONT_SCALE, THICKNESS, &baseLine);
top = max(top, label_size.height);
Point tlc = Point(left, top);
Point brc = Point(left + label_size.width, top + label_size.height + baseLine);
rectangle(input_image, tlc, brc, BLACK, FILLED);
putText(input_image, label, Point(left, top + label_size.height), FONT_FACE, FONT_SCALE, YELLOW, THICKNESS);
}
// 预处理
vector<Mat> pre_process(Mat &input_image, Net &net)
{
Mat blob;
blobFromImage(input_image, blob, 1./255., Size(INPUT_WIDTH, INPUT_HEIGHT), Scalar(), true, false);
net.setInput(blob);
vector<Mat> outputs;
net.forward(outputs, net.getUnconnectedOutLayersNames());
return outputs;
}
// 后处理
Mat post_process(Mat &input_image, vector<Mat> &outputs, const vector<string> &class_name)
{
vector<int> class_ids;
vector<float> confidences;
vector<Rect> boxes;
float x_factor = input_image.cols / INPUT_WIDTH;
float y_factor = input_image.rows / INPUT_HEIGHT;
float *data = (float *)outputs[0].data;
const int dimensions = 85;
const int rows = 25200;
for (int i = 0; i < rows; ++i)
{
float confidence = data[4];
if (confidence >= CONFIDENCE_THRESHOLD)
{
float * classes_scores = data + 5;
Mat scores(1, class_name.size(), CV_32FC1, classes_scores);
Point class_id;
double max_class_score;
minMaxLoc(scores, 0, &max_class_score, 0, &class_id);
if (max_class_score > SCORE_THRESHOLD)
{
confidences.push_back(confidence);
class_ids.push_back(class_id.x);
float cx = data[0];
float cy = data[1];
float w = data[2];
float h = data[3];
int left = int((cx - 0.5 * w) * x_factor);
int top = int((cy - 0.5 * h) * y_factor);
int width = int(w * x_factor);
int height = int(h * y_factor);
boxes.push_back(Rect(left, top, width, height));
}
}
data += 85;
}
vector<int> indices;
NMSBoxes(boxes, confidences, SCORE_THRESHOLD, NMS_THRESHOLD, indices);
for (int i = 0; i < indices.size(); i++)
{
int idx = indices[i];
Rect box = boxes[idx];
int left = box.x;
int top = box.y;
int width = box.width;
int height = box.height;
rectangle(input_image, Point(left, top), Point(left + width, top + height), BLUE, 3*THICKNESS);
string label = format("%.2f", confidences[idx]);
label = class_name[class_ids[idx]] + ":" + label;
draw_label(input_image, label, left, top);
}
return input_image;
}
// 主函数
int main(int argc, char **argv)
{
vector<string> class_list;
ifstream ifs("class.txt");
string line;
while (getline(ifs, line))
{
class_list.push_back(line);
}
Mat frame;
frame = imread(argv[1]);
Net net;
net = readNet("yolov5s.onnx");
vector<Mat> detections;
detections = pre_process(frame, net);
Mat img = post_process(frame.clone(), detections, class_list);
vector<double> layersTimes;
double freq = getTickFrequency() / 1000;
double t = net.getPerfProfile(layersTimes) / freq;
string label = format("Inference time : %.2f ms", t);
putText(img, label, Point(20, 40), FONT_FACE, FONT_SCALE, RED);
imshow("Output", img);
waitKey(0);
return 0;
}一切准备就绪,马上开始编译,进入到工程目录,打开 powershell,然后一次执行
mkdir build
cmake -B build
cmake --build build --config Release编译成功后,就可以找图片来测试了
.\build\Release\yolov5dnn.exe bus.jpg
可以看到图片的检测时间花费了210毫秒,显然是没有用到 gpu,如果需要启用 gpu 加速的话,就需要重新编译 opencv,使能 cuda,这部分内容可以去参考 windows 编译 opencv,支持 cuda 加速 和 ubuntu 下编译 opencv,支持 cuda 加速


