环境
- windows 10 64bit
- python 3.8
- pytorch 1.7 + cu101
- ffmpeg
前言
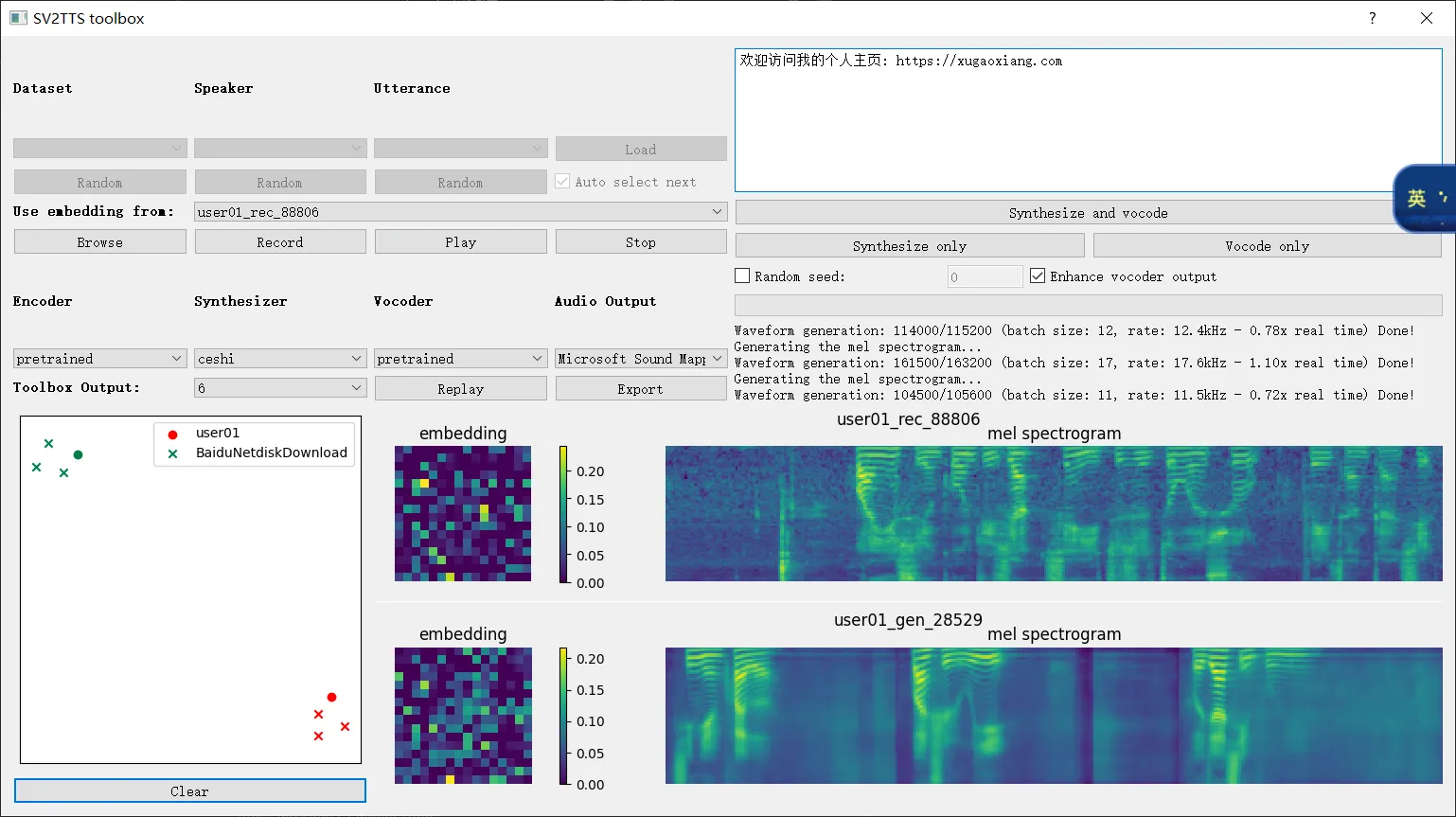
今天给大家介绍一个语音合成的工具,MockingBird,仅仅使用5秒钟就可以模拟出你想要的声音,难能可贵的是,MockingBird还支持普通话。
安装
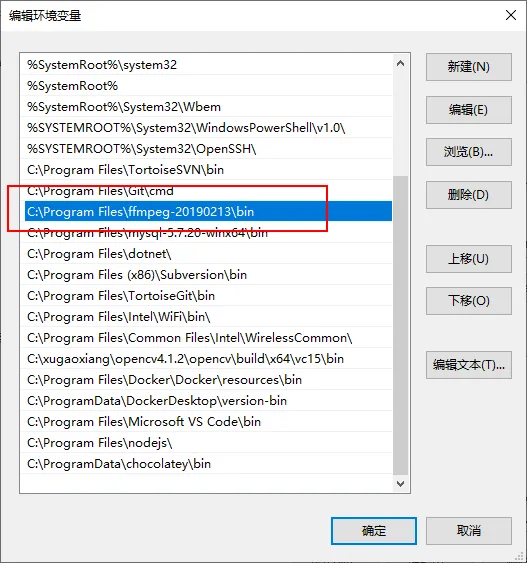
首先安装ffmpeg,它是用来进行音视频处理的。从官网下载编译好的二进制文件 http://ffmpeg.org/download.html,尽量下载较新的版本,并将其路径加入到系统环境变量中
创建一个全新的python虚拟环境
conda create -n pytorch1.7 python=3.8
conda activate pytorch1.7接下来去下载MockingBird源码,并安装相应依赖
git clone https://github.com/babysor/MockingBird.git
cd MockingBird
# 安装gpu版torch和torchvision
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
# 安装其他依赖
pip install -r requirements.txt
# 这个库是用来进行噪音过滤的
pip install webrtcvad
# 如果是linux的话,使用apt安装ffmpeg
sudo apt install ffmpeg portaudio19-dev
pip install pyaudio为了进行测试,还需要下载预训练模型
链接:https://pan.baidu.com/s/1nj3GWZWWOvh6QFpl9LSAzw
提取码:nbmc
下载完成后,将saved_models文件夹放在源码目录下的synthesizer文件夹下
测试
使用作者提供的预训练模型测试时,会报错
RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).这个错误需要修改源码文件synthesizer/utils/symbols.py,将
_characters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz1234567890!\'(),-.:;? '改成
_characters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz12340!\'(),-.:;? '然后就可以开始进行测试了
python demo_toolbox.py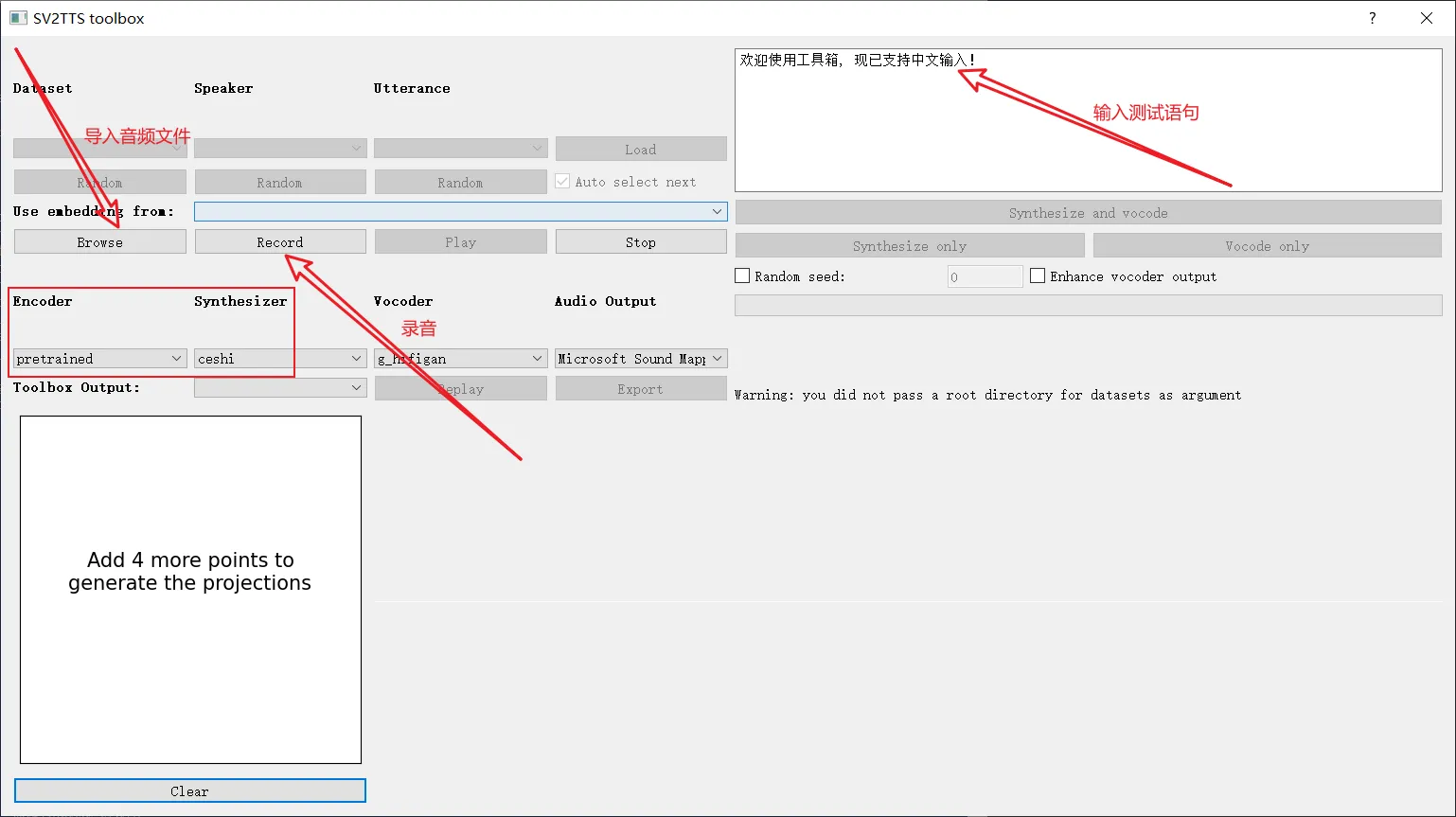
这里直接录音测试,点击Record,完成后点击Play可以播放。Encoder选择pretrained,Synthesizer选择ceshi,点击右上框的Synthesize and vocode,完成后就可以听到合成后的声音了