简介
K -近邻即 K Nearest Neighbor,简写为 KNN,它是一种分类和回归算法,是最简单的机器学习算法之一。它的思路是:在特征空间中,如果一个样本附近的 k 个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。
经典案例
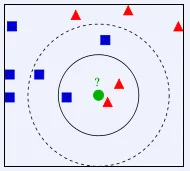
看上面的图,已知有2个类别,红色的三角形和蓝色的正方形,现在我们要判断中间的那个绿色的圆是属于哪一类?使用 KNN,就从它的邻居下手,但需要看多少个邻居呢?
K=3,绿色圆点的最近的3个邻居是2个红色三角形和1个蓝色正方形,少数从属于多数,基于统计的方法,就认为绿色的圆属于红色三角形这一类K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色正方形,还是少数从属于多数,基于统计的方法,就认为绿色的圆属于蓝色正方形这一类
可以看到,K 值的选择,对我们最后的结果影响很大。K 值越小,很容易受到单个个体的影响,K 值太大,很容易受到较远的特殊距离的影响。这里讲到的距离,常见的计算方法有
那 K 值应该如何设定呢?
很不幸,这里没有一个明确的结论。K 的取值受到问题本身和数据集大小的影响,很多时候,需要自己进行多次的尝试,然后选择最佳的值。
KNN的缺点
KNN 需要计算与所有样本之间的距离,这样的话,计算量就很大,效率很低,很难应用到较大的数据集当中。
代码示例
sklearn 这个库,提供了完整的 KNN 实现,使用起来也非常简单,通过 pip install scikit-learn 安装
from sklearn.neighbors import KNeighborsClassifier
...
# n_neighbors就是K值
knn_classifier = KNeighborsClassifier(n_neighbors=5)
knn_classifier.fit(x_train, y_train)
# X_test是待分类的数据
pred = knn_classifier.predict(X_test)

