软硬件环境
- windows 10 64bits
- anaconda with python 3.7
- xlrd 1.2.0
- xlwt 1.3.0
简介
数据处理是 python 编程语言的一大应用领域,而 excel 又是当下最流行的数据处理软件,因此用 python 进行数据处理时,很容易就会碰到 excel 的处理问题。
工具
这里我们使用 xlrd 和 xlwt 来进行 excel 文件的读写
我们使用 pip 进行安装
pip install xlrd xlwt写入excel
直接来看示例
import xlwt
# 创建xls文件对象
workbook = xlwt.Workbook()
# 新增两个表单页
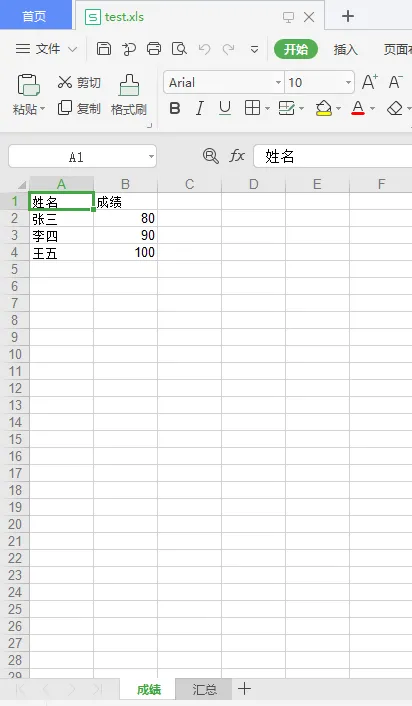
sheet1 = workbook.add_sheet('成绩')
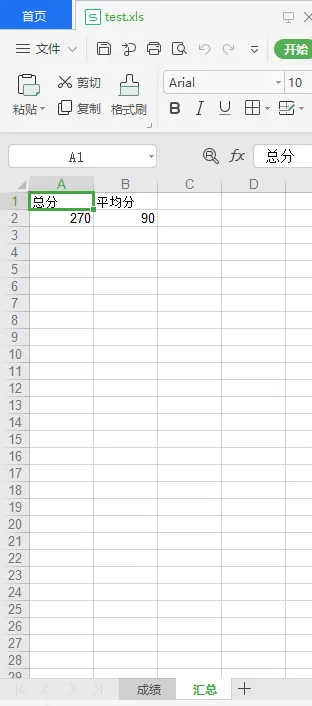
sheet2 = workbook.add_sheet('汇总')
# 按照单元格来添加数据,第一个参数是行,第二个参数是列
# 操作第一个sheet
sheet1.write(0, 0, '姓名')
sheet1.write(0, 1, '成绩')
sheet1.write(1, 0, '张三')
sheet1.write(1, 1, 80)
sheet1.write(2, 0, '李四')
sheet1.write(2, 1, 90)
sheet1.write(3, 0, '王五')
sheet1.write(3, 1, 100)
# 操作第二个sheet
sheet2.write(0, 0, '总分')
sheet2.write(0, 1, '平均分')
sheet2.write(1, 0, 270)
sheet2.write(1, 1, 90)
# 保存文件
workbook.save('test.xls')执行以上代码后,在当前目录下生成 test.xls
读取excel
针对上面生成的 test.xls,使用 xlrd 进行读取,来看代码
import xlrd
# 打开上面创建的test.xls文件
wb = xlrd.open_workbook("test.xls")
# sheet数量
print(f"sheet数量: {wb.nsheets}")
# 获取并打印 sheet 名称
print(f"sheet名称: {wb.sheet_names()}")
# 根据索引获取
sheet1 = wb.sheet_by_index(0)
# 或者根据sheet的名称获取
# sheet1 = wb.sheet_by_name('成绩')
# sheet名称、行数和列数
print(f"sheet {sheet1.name}, 共有{sheet1.nrows}行{sheet1.ncols}列")
# 获取某个单元格的值
print(f"第一行第二列的值为: {sheet1.cell_value(0, 1)}")
# 获取整行或整列的值
rows = sheet1.row_values(0)
cols = sheet1.col_values(1)
# 获取的行列值
print(f"第一行的值为: {rows}")
print(f"第二列的值为: {cols}")
# 遍历所有表单内容
for sheet in wb.sheets():
for r in range(sheet.nrows):
print(sheet.row(r))执行上述代码,得到输出
sheet数量: 2
sheet名称: ['成绩', '汇总']
sheet 成绩, 共有4行2列
第一行第二列的值为: 成绩
第一行的值为: ['姓名', '成绩']
第二列的值为: ['成绩', 80.0, 90.0, 100.0]
[text:'姓名', text:'成绩']
[text:'张三', number:80.0]
[text:'李四', number:90.0]
[text:'王五', number:100.0]
[text:'总分', text:'平均分']
[number:270.0, number:90.0]备注
处理 excel 的开源方法有很多,更多第三方库请参考文末的参考资料



