简介
PyCaret 是一个用于机器学习的 Python 库,它旨在简化机器学习流程并提供一个易于使用的接口。它为用户提供了一个高级的 API,可以在几行代码中完成常见的机器学习任务,如数据预处理、特征工程、模型选择、调参和模型评估。PyCaret 本质上是对 scikit-learn、XGBoost、LightGBM、CatBoost、Optuna、Hyperopt、Ray 等多个机器学习库和框架的 Python 封装。PyCaret 的灵感来源于 R 编程语言中的 caret 库。
想象一下你正在烹饪一道美食。你需要准备食材、切割、炒煮、调味和品尝。PyCaret 就像是你的私人厨师助手,它会帮助你自动完成这些步骤,让你能够专注于享受美食。
基本使用
让我们通过一个例子来说明 PyCaret 的使用方法。
使用之前需要安装一下,要求 python 3.7 版本以上
pip install pycaret这里有一份加州房屋的数据集(来自 csv 文件,文末有下载地址),其中包含房屋的各种特征(如经度、纬度、房间数、卧室数量、中位价格等)。
首先,你需要加载数据集并进行预处理。使用 PyCaret,你只需要一行代码就可以完成这个步骤,这里用到了 pandas
import pandas as pd
from pycaret.regression import *
data = pd.read_csv('housing.csv')接下来,你需要选择一个模型来训练。PyCaret 提供了许多常见的机器学习模型供你选择。你可以通过一行代码来选择一个线性回归模型
model = setup(data, target='median_house_value')这将自动进行特征工程、数据划分和模型训练。PyCaret 会根据你的数据集自动选择最佳的特征转换方法和模型。
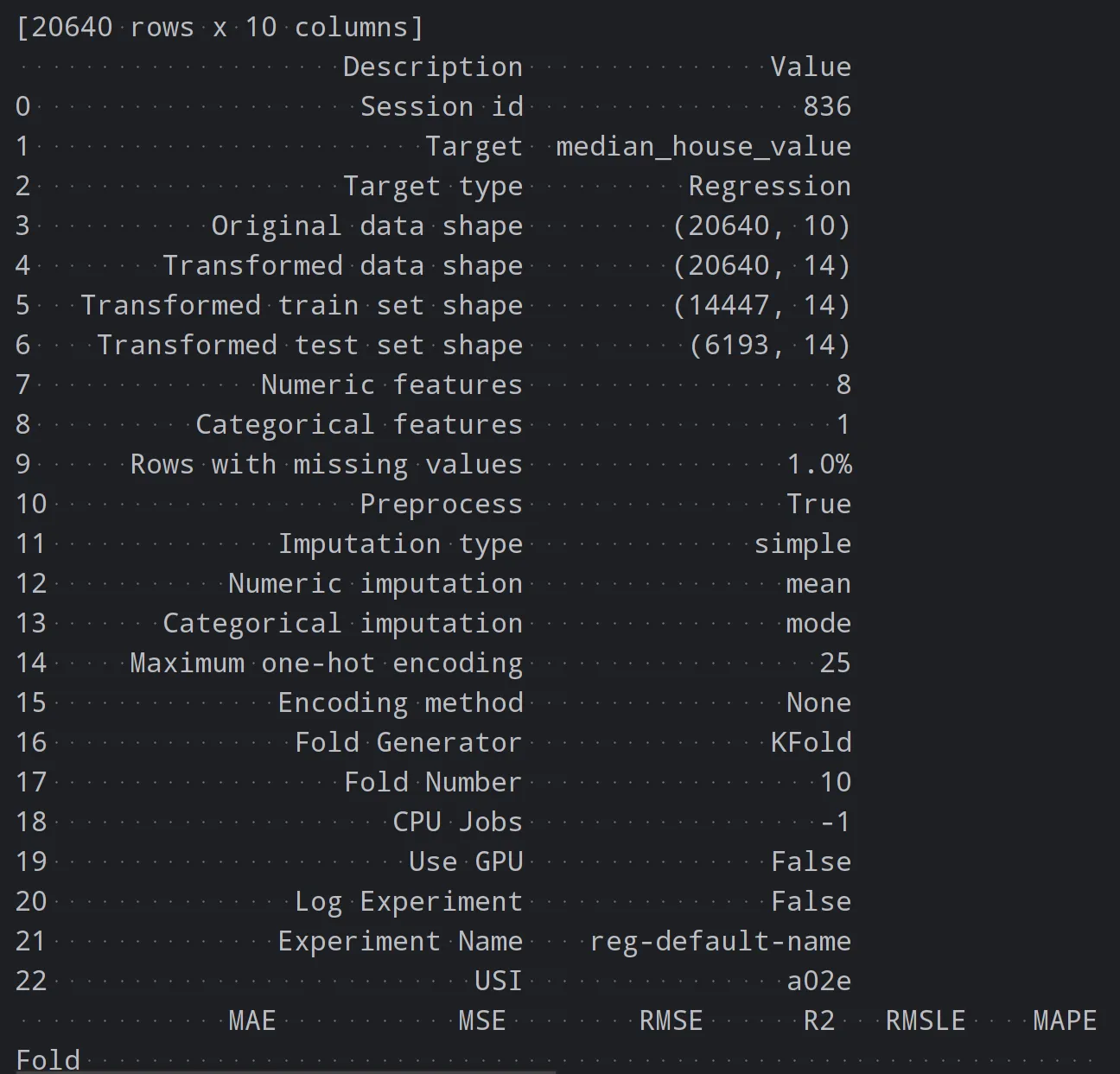
然后,你可以使用 PyCaret 的自动调参功能来优化模型的超参数。它会自动尝试不同的参数组合,并选择表现最好的模型
dt = create_model('lr')
best_model = tune_model(dt)最后,你可以使用 PyCaret 的评估功能来评估模型的性能。它会提供各种指标,如均方误差、R 平方等,帮助你了解模型的表现
evaluate_model(best_model)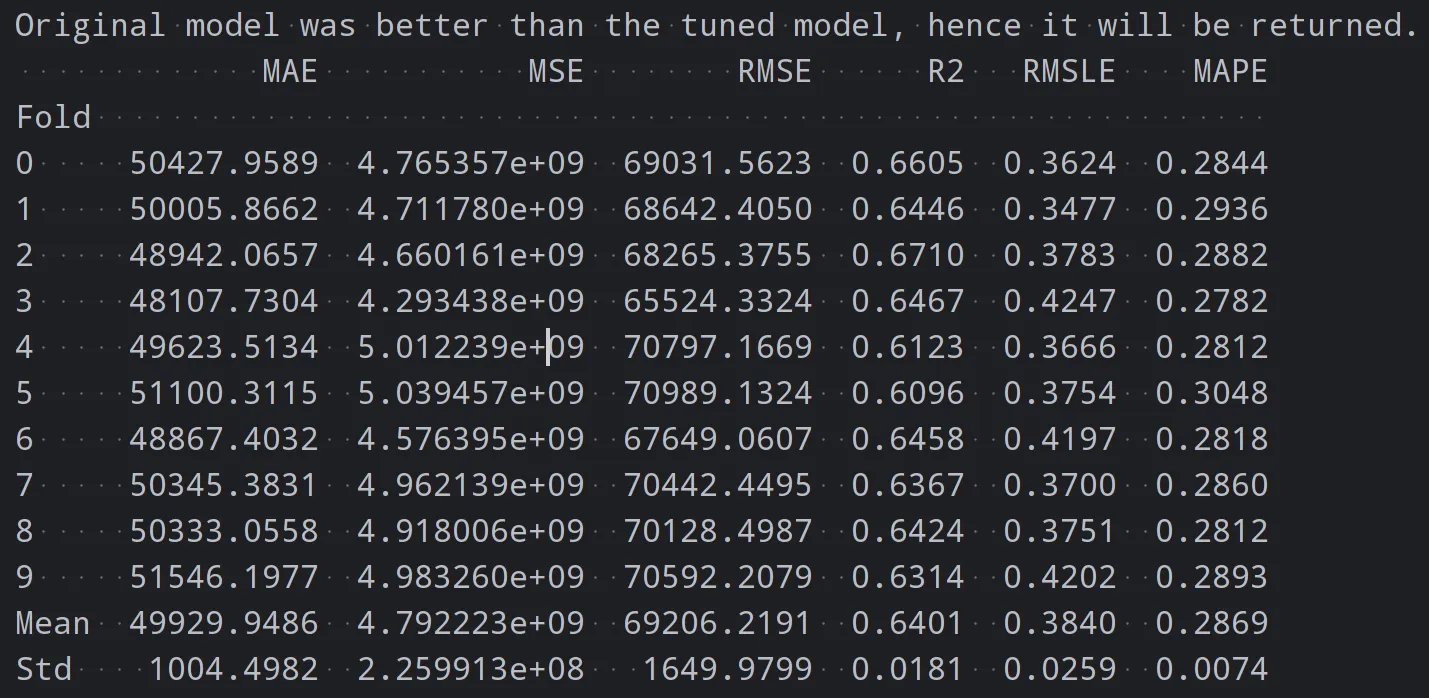
保存模型文件
# 模型文件 best_pipeline.pkl,同时还有日志文件 logs.log
save_model(best_model, 'best_pipeline')通过这些简单的步骤,你就能够构建一个机器学习模型,并使用 PyCaret 轻松完成整个流程。
GPU加速
要想使用 GPU 来加速模型训练,只需要在 setup 方法中传递 use_gpu = True 即可。其它 API 的使用没有任何变化。
常见使用案例
官方提供了一些常见场景下的代码示例,大家可以参考参考
Anomaly Detection

Classification

Time Series
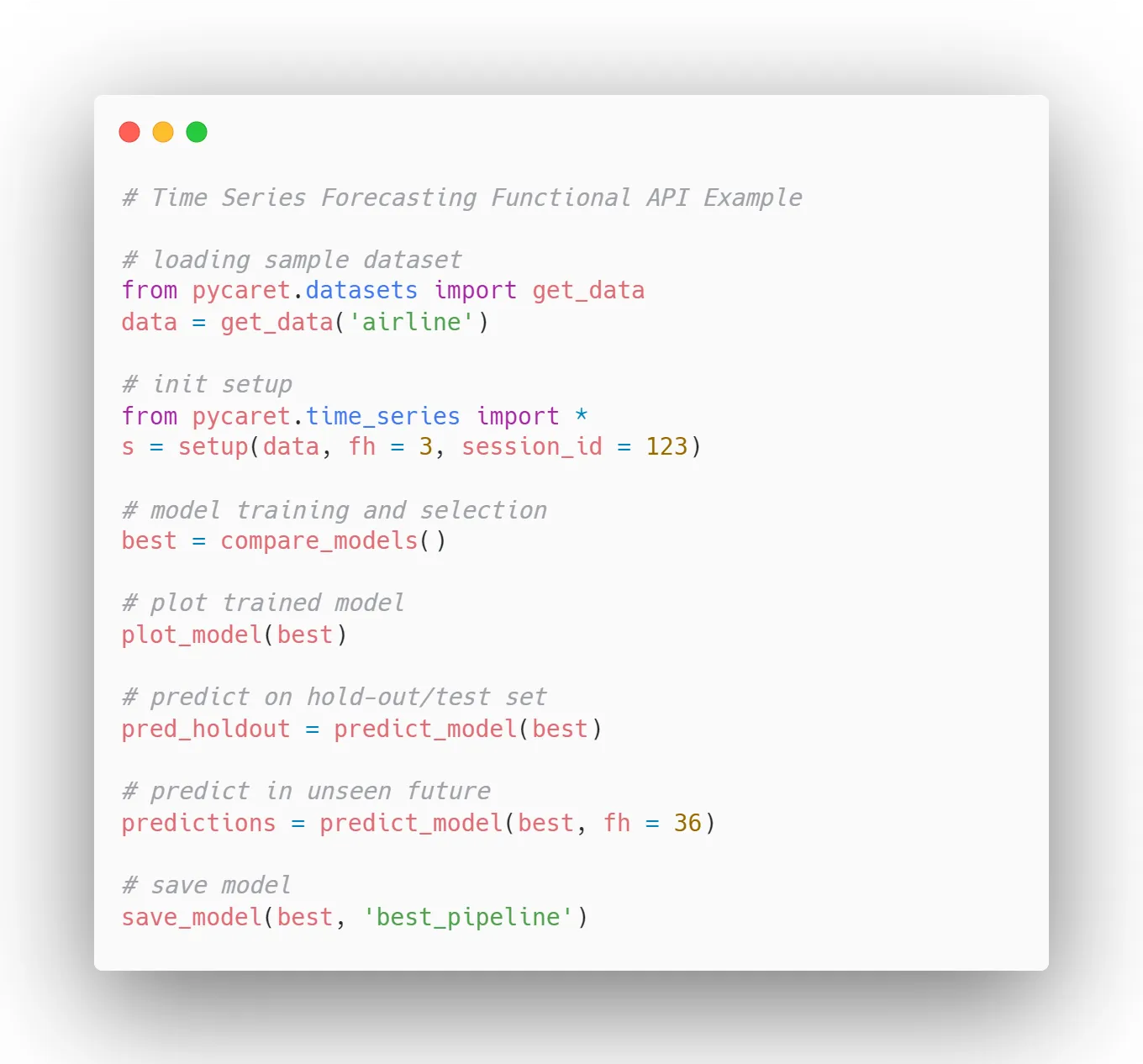
Clustering

数据集下载地址
链接:https://pan.quark.cn/s/1d55880ca74e



