环境
- windows 10 64bit
- voc dataset
简介
有些时候,针对大的一个数据集(比如 VOC2012),我们只需要去做某个目标(比如 person)的模型训练,这时候,就需要将特定目标的图片和对应的标注整理出来,形成一个新的数据集。本篇,我们就来实现这个目标。
操作步骤
这里以 VOC2012 数据集为例,来到 roboflow 官方的公开数据集,选择 Pascal VOC 2012 Dataset

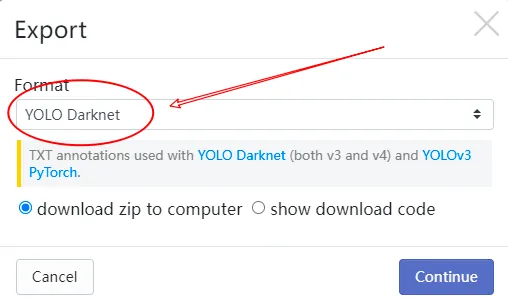
下载时,选择 YOLO Darknet 格式
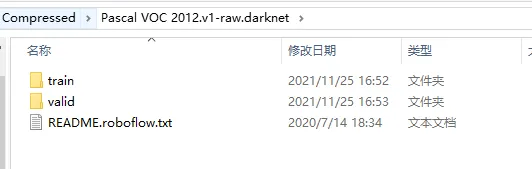
下载完成后,解压,目录结构是这样的
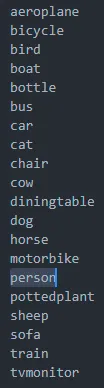
完整的 VOC2012 包含了20个目标,这个在文件 _darknet.labels 中有描述
这里假设要抽取出 person 这个 class,我们在数据集根目录新建脚本,输入如下代码
import os
import shutil
# 统计下最后图片的数量
counter = 0
# 创建2个目标文件夹,images放图片,labels放标注
if not os.path.exists('images'):
os.makedirs('images')
if not os.path.exists('labels'):
os.makedirs('labels')
for file in os.listdir('train'):
flag = False
if file.endswith('.txt'):
f = open("train/{}".format(file), 'r')
line = f.readline()
# 原数据集中有部分txt,大小为0,内容为空,去除掉
if line == "":
continue
while line:
# 去除txt中的第一列的值,也就是class id
tmp = line.split(' ')[0]
# txt中的数据是字符串类型,人这个目标的id是14
if tmp != "14":
print('NOT person.')
flag = True
break
line = f.readline()
f.close()
if not flag:
counter += 1
prefix = file[0: -3]
# 拷贝符合条件的图片和对应的标注
shutil.copy2('train/{}jpg'.format(prefix), 'images')
shutil.copy2('train/{}'.format(file), 'labels')
print('total number image: {}'.format(counter))
执行上述脚本后,就会将符合条件的图片存放在 images 文件夹,而标注则是存放在 labels 文件夹
那接下来就要去修改标注中的 class id 了,在 VOC2012 中,人的 id 是14(从0开始),考虑到新的数据集只有人这一类,所以 id 就是0,那工作就变成要将 txt 文件中的第一列数据中的 14 改为 0
本质上这个就是查找替换的操作,实现的方法很多。这里给大家介绍个 windows 下的一个开源工具 grepWin,它拥有图形界面,操作非常简单,下载地址是
https://github.com/stefankueng/grepWin/releases/tag/2.0.8
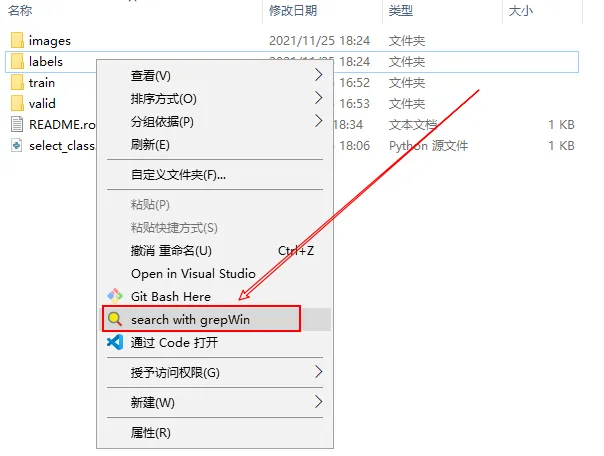
安装后,右键点击文件夹 labels,选择 search with grepWin 打开
查找可以使用正则,也可以使用文本。
本例中使用完整文本匹配,需要将 14 替换成 0 ,注意后边带一个空格,这样能多过滤一些匹配,先不着急替换,可以先查找看看结果
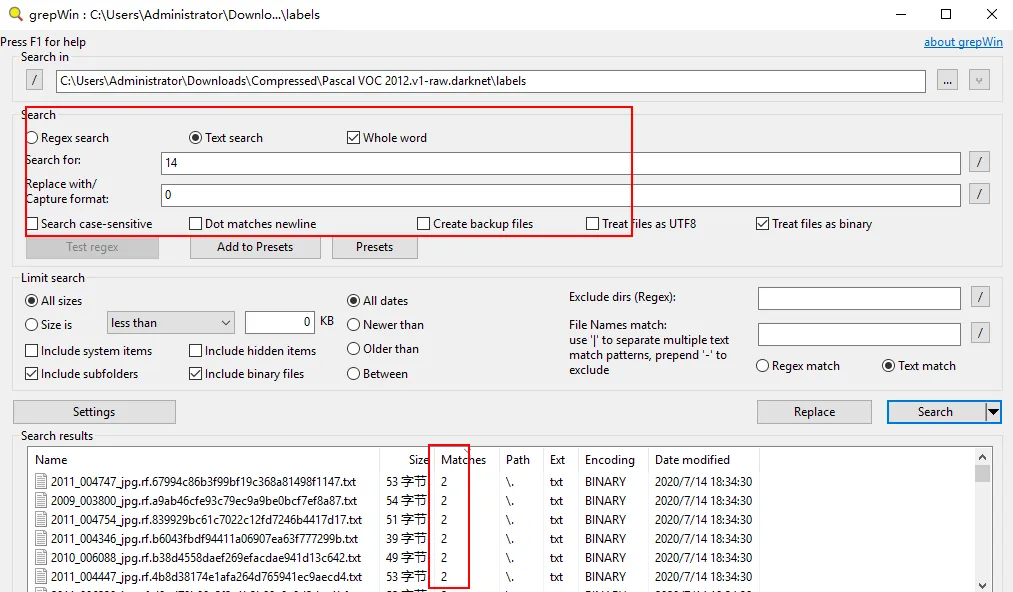
有些 txt 文件,可能存在多个匹配,点击上方的 Matches 可以重新排序

打开其中的一个 txt 进行查看,发现,其它列也有可能匹配 14 ,因此针对这种情况,就需要手动去修改,幸好,这样的文件不算特别多。
都是单个匹配的话,就可以直接替换文本了。
至此,单个目标的数据集就已经处理完毕了,可以拿去训练了



