软硬件环境
- windows 10 64bits
- anaconda with python 3.7
- apscheduler 3.6.3
视频看这里
此处是 youtube 的播放链接,需要科学上网。喜欢我的视频,请记得订阅我的频道,打开旁边的小铃铛,点赞并分享,感谢您的支持。
前言
说起定时任务,第一反应应该是 windows 自带的计划任务或者 linux 自带的 crontab,关于 ubuntu 操作系统下如何使用 crontab 可以参考下面这支视频。 apscheduler 是一款使用 python 语言开发的定时任务工具,提供了非常丰富而且简单易用的定时任务接口
安装
安装非常简单, 使用 pip
pip install apschedulerapscheduler的四大组件
- triggers 触发器 可以按照日期、时间间隔或者
contab表达式三种方式触发 - job stores 作业存储器 指定作业存放的位置,默认保存在内存,也可以保存在各种数据库中
- executors 执行器 将指定的作业提交到线程池或者进程池中运行
- schedulers 作业调度器 常用的有
BackgroundScheduler(后台运行)和BlockingScheduler(阻塞式)
代码实践
下面通过几个示例来看看如何来使用 apscheduler
import time
from apscheduler.schedulers.background import BlockingScheduler
from apscheduler.triggers.interval import IntervalTrigger
def my_job():
print('my_job, {}'.format(time.ctime()))
if __name__ == "__main__":
scheduler = BlockingScheduler()
# 间隔设置为1秒,还可以使用minutes、hours、days、weeks等
intervalTrigger=IntervalTrigger(seconds=1)
# 给作业设个id,方便作业的后续操作,暂停、取消等
scheduler.add_job(my_job, intervalTrigger, id='my_job_id')
scheduler.start()
print('=== end. ===')
执行代码,输出是这样的
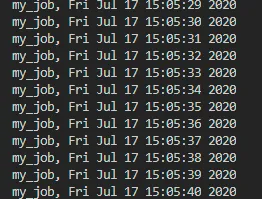
因为我们使用了 BlockingScheduler,它是阻塞式的,所以只看到了 my_job 方法中的输出,而语句 print('=== end. ===') 并没有被执行。BackgroundScheduler 它可以在后台运行,不会阻塞主线程的执行,来看下面的代码
import time
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.triggers.interval import IntervalTrigger
def my_job():
print('my_job, {}'.format(time.ctime()))
if __name__ == "__main__":
scheduler = BackgroundScheduler()
intervalTrigger=IntervalTrigger(seconds=1)
scheduler.add_job(my_job, intervalTrigger, id='my_job_id')
scheduler.start()
print('=== end. ===')
while True:
time.sleep(1)
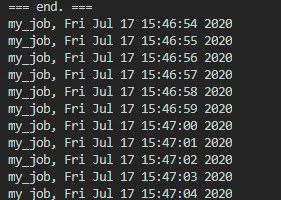
代码执行的结果是这样的
如果把 triggers 设置成 DateTrigger,就变成作业在某一个时间点执行,示例如下
import time
import datetime
from apscheduler.schedulers.background import BlockingScheduler
from apscheduler.triggers.date import DateTrigger
def my_job():
print('my_job, {}'.format(time.ctime()))
if __name__ == "__main__":
scheduler = BlockingScheduler()
intervalTrigger=DateTrigger(run_date='2020-07-17 16:18:55')
scheduler.add_job(my_job, intervalTrigger, id='my_job_id')
scheduler.start()
等到设定的时间到了,作业就会被自行一次

如果想按照指定的周期去执行的话,就需要使用 CronTrigger 了,工作原理跟 UNIX 中 crontab 定时任务非常相似,它可以指定非常详细且复杂的规则。同样的来看示例代码
import time
from apscheduler.schedulers.background import BlockingScheduler
from apscheduler.triggers.cron import CronTrigger
def my_job():
print('my_job, {}'.format(time.ctime()))
if __name__ == "__main__":
scheduler = BlockingScheduler()
# 第一秒执行作业
intervalTrigger=CronTrigger(second=1)
# 每天的19:30:01执行作业
# intervalTrigger=CronTrigger(hour=19, minute=30, second=1)
# 每年的10月1日19点执行作业
# intervalTrigger=CronTrigger(month=10, day=1, hour=19)
scheduler.add_job(my_job, intervalTrigger, id='my_job_id')
scheduler.start()
代码执行的效果是这样的
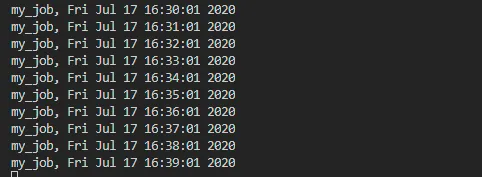
上面的代码中并没有使用 executors,因为只有一个作业,但是从调试中可以发现,默认情况下,apscheduler 也是使用了 ThreadPoolExecutor,且线程池的大小是10
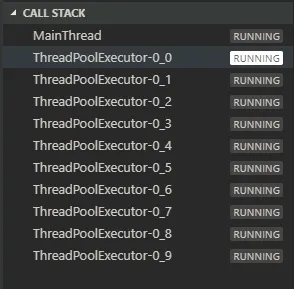
下面我们看看 executors 的使用
import time
from apscheduler.schedulers.background import BlockingScheduler
from apscheduler.triggers.interval import IntervalTrigger
from apscheduler.executors.pool import ThreadPoolExecutor
def my_job():
print('my_job, {}'.format(time.ctime()))
if __name__ == "__main__":
executors = {
'default': ThreadPoolExecutor(20)
}
scheduler = BlockingScheduler(executors=executors)
intervalTrigger=IntervalTrigger(seconds=1)
scheduler.add_job(my_job, intervalTrigger, id='my_job_id')
scheduler.start()
可以看到,我们将线程池的大小改为了20,在初始化 scheduler 的时候将 executors 传递进去,后面的操作就跟之前的完全一样了
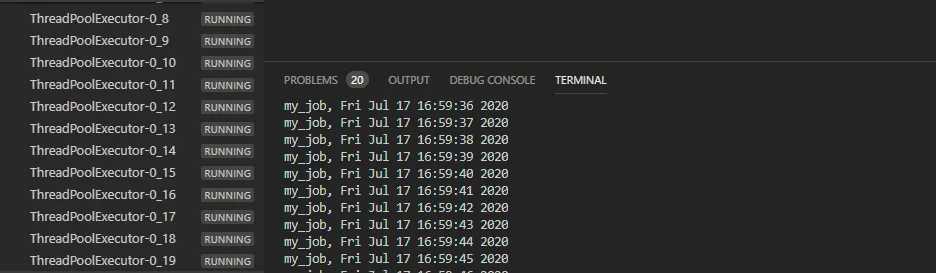
关于 ThreadPoolExecutor 和 ProcessPoolExecutor 的选择问题,这里有一个原则,如果是 cpu 密集型的作业,使用 ProcessPoolExecutor,其它的使用 ThreadPoolExecutor,当然 ThreadPoolExecutor 和 ProcessPoolExecutor 也是可以混用的
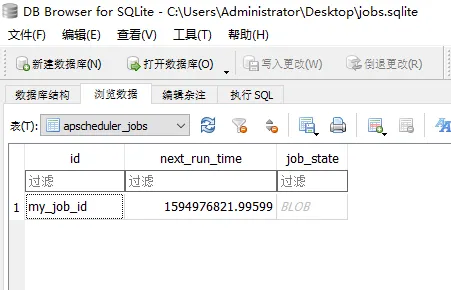
最后我们来看看作业存储器,我们把它改成存储到 sqlite 中
import time
from apscheduler.schedulers.background import BlockingScheduler
from apscheduler.triggers.interval import IntervalTrigger
from apscheduler.executors.pool import ThreadPoolExecutor
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
def my_job():
print('my_job, {}'.format(time.ctime()))
jobstores = {
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
if __name__ == "__main__":
executors = {
'default': ThreadPoolExecutor(20)
}
scheduler = BlockingScheduler(jobstores=jobstores, executors=executors)
intervalTrigger=IntervalTrigger(seconds=1)
scheduler.add_job(my_job, intervalTrigger, id='my_job_id')
scheduler.start()
代码执行后,会在源码目录下生成 sqlite 数据库文件 jobs.sqlite,我们使用图形化工具打开查看,可以看到数据库中存放的作业的 id 和作业下次执行的时间