软硬件环境
- ubuntu 18.04 64bit
- anaconda with 3.7
- nvidia gtx 1070Ti
- cuda 10.1
- pytorch 1.5
- YOLOv5
视频看这里
此处是youtube的播放链接,需要科学上网。喜欢我的视频,请记得订阅我的频道,打开旁边的小铃铛,点赞并分享,感谢您的支持。
YOLOv5环境配置
请参考之前的文章,YOLOv5目标检测
使用COCO数据集
YOLOv5的预训练模型是基于 COCO 数据集,如果自己想去复现下训练过程,可以依照下面的命令
$ python train.py --data coco.yaml --cfg yolov5s.yaml --weights '' --batch-size 64
yolov5m 48
yolov5l 32
yolov5x 16COCO的数据集可以通过data文件夹下get_coco2017.sh脚本进行下载,包含图片和lable文件。COCO的数据集实在是太大了,整个压缩包有18G,考虑到自己到的网速还有机器的算力,还是洗洗睡吧。。。
制作自己的数据集
如果没有对应目标的公开数据集,那就只有自己出手收集了,图片到手后,接下来就是艰辛的打标签工作了,这里使用工具LabelImg,下载地址是
https://github.com/tzutalin/labelImg/releases/tag/v1.8.1
LabelImg使用Qt做了图形化的界面,操作还是很方便的,这也是选择它的理由,它提供了默认的class,如果你不需要这些类型的话,可以将其删除
接下来就可以打开exe文件,点击Open导入图片,按下快捷键w,选定目标后,会弹出输入框,写上class名称,就可以了,如果有多个目标,那就继续标
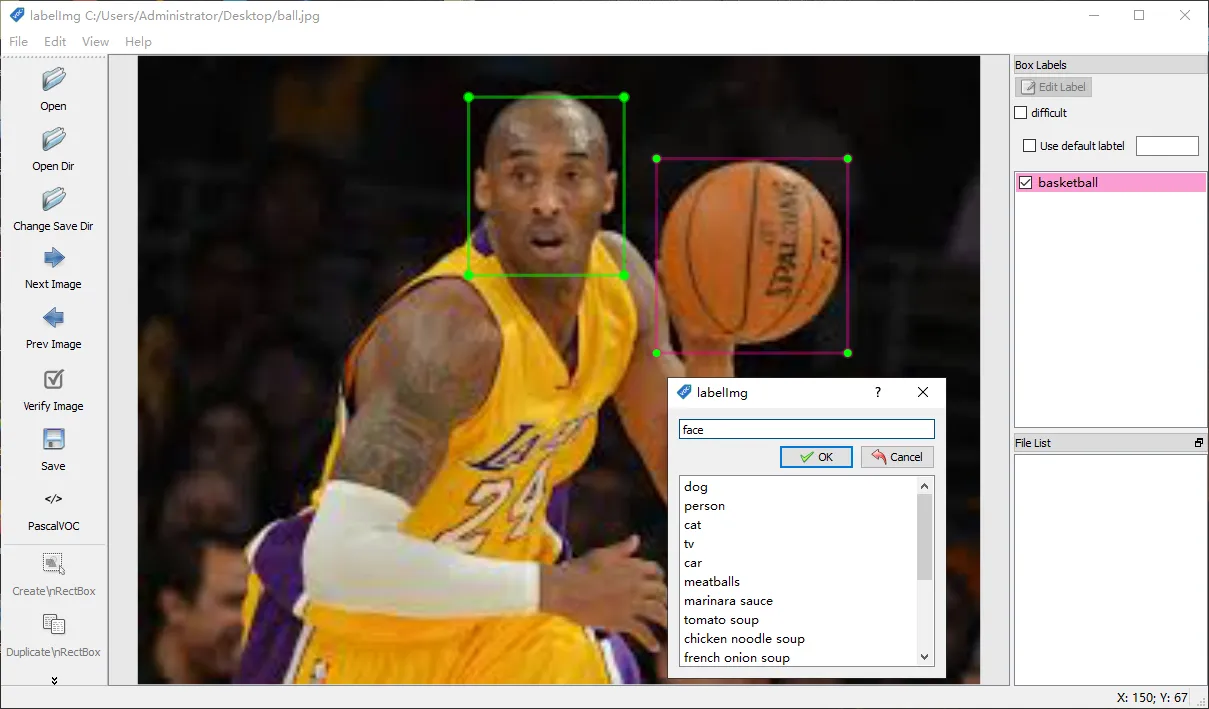
labelImg还支持文件夹的导入,在标完一张后,在左侧选择Next Image就可以切换到下一张继续了。输出格式部分,目前labelImg支持YOLO和PascalOVC2种格式,前者标签信息是存储在txt文件中,而后者是存储在xml中
打完标签后,就可以进行保存了,图片和标签文件我们分开存放,但是文件名是对应的,只是扩展名不同
最后来看看标签文件的内容
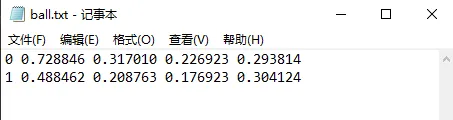
一行代表一个目标,格式是
class x_center y_center width height第一列是class的索引,计数从0开始,比如这里的0代表的是basketball,1代表的是face;后4列是x_center/image_width、y_center/image_height、width/image_width、height/image_height,取值范围是0 ~ 1
使用公开的数据集进行训练
ROBOFLOW 提供了一些公开的数据集,我们下载其中的口罩数据集进行训练,链接是 https://public.roboflow.ai/object-detection/mask-wearing, 如果原网站无法访问的话,可以到下面的链接下载
下载下来是一个压缩包,解压后,文件夹内的文件结构是这样的
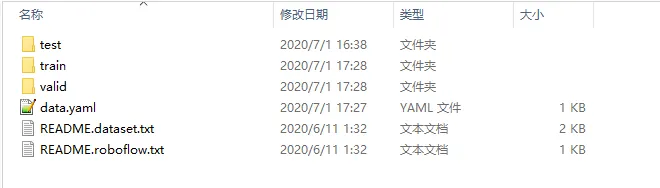
其中文件夹train包含了参加训练的图片以及对应的label文件,两者只有扩展名不同而已,目前图片只有105张。我们将包含数据集的文件夹重命名为mask,存储在yolov5工程的同级目录下
接着修改mask/data.yaml文件内容为
(base) xugaoxiang@1070Ti:~/Works/github/mask$ cat data.yaml
train: ../mask/train/images
val: ../mask/valid/images
nc: 2
names: ['mask', 'no-mask']最后修改yolov5/models/yolov5s.yaml,将nc = 80修改为nc = 2,因为数据集中只有mask和no-mask2个类别
接下来执行训练命令
cd yolov5
python train.py --img 640 --batch 16 --epochs 300 --data ../mask/data.yaml --cfg models/yolov5s.yaml --weights '' 训练结束后,在weights文件夹下就生成了best.pt和last.pt,到mask/test/images找些图片测试一下
python detect.py --weight weights/best.pt --source ../mask/test/images/1224331650_g_400-w_g_jpg.rf.b816f49e2d84044fc997a8cbd55c347d.jpg

效果还算ok。感兴趣的话,自己动手试试吧
v3.0版本
很多朋友反应,在训练时出现下面的错误
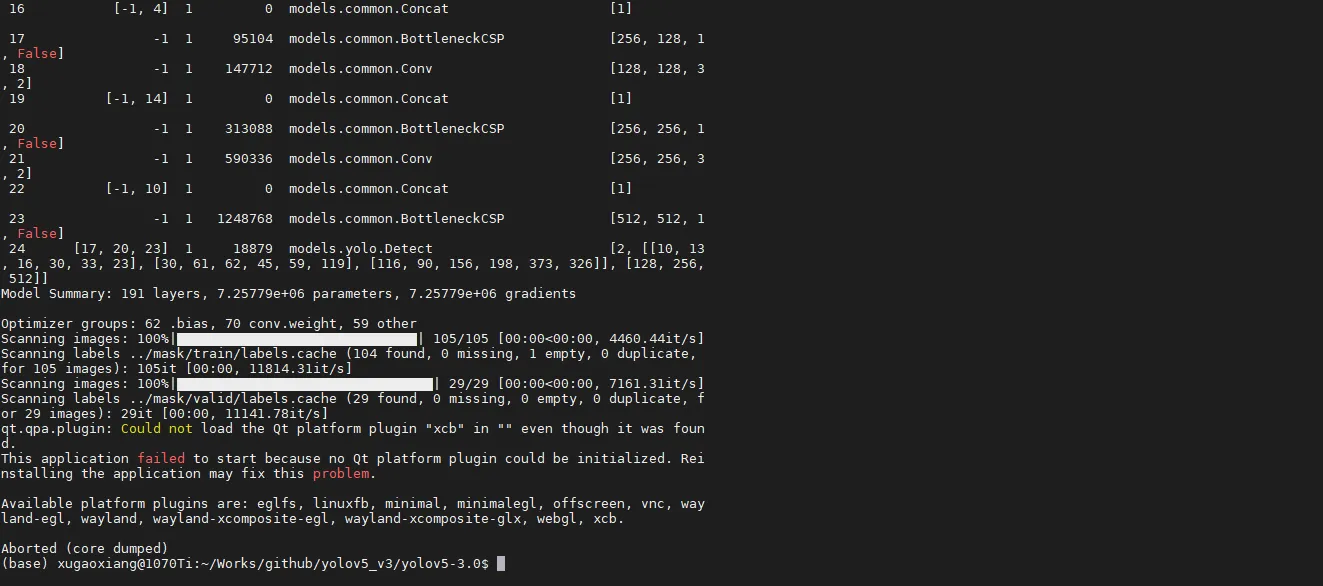
这个错误是由于python环境中的pyqt引起的,卸载pyqt就好
pip uninstall pyqt5这里多说一句,如果使用的是anaconda的环境,在安装好后,在base的环境中不要去安装任何第三方库。针对不同的项目或者工程,创建独立的虚拟环境,然后安装依赖的库,就不会出现类似的错误了。
另外,在windows上训练模型,如果出现
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.解决的方法是在train.py文件开头部分,添加语句
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'






























