软硬件环境
- Intel(R) Xeon(R) CPU E5-1607 v4 @ 3.10GHz
- GTX 1070 Ti 32G
- ubuntu 18.04 64bit
- anaconda with python 3.6
- darknet git version
- cuda 8.0
- opencv 3.1.0
视频看这里
Darknet简介
Darknet 是一个用 C 和 CUDA 编写的开源的神经网络框架。安装起来非常快速、简单,并同时支持 CPU 和 GPU。源码托管在 github 上,地址是: https://github.com/pjreddie/darknet
YOLO
You Only Look Once (YOLO) 是目前最先进的、实时的物体检测系统,已经发展到了第三个版本,在速度和准确度上都有非常大的提升
安装Darknet
步骤非常简单, 以下是 CPU 版本
git clone https://github.com/pjreddie/darknet.git
cd darknet
make如果需要 GPU 加速的话,需要修改 Makefile, 将 GPU=0 改成 GPU=1,然后重新 make, 由于我的系统是最新的18.04版本,GCC 版本已经升级到了7,编译中出现了如下错误
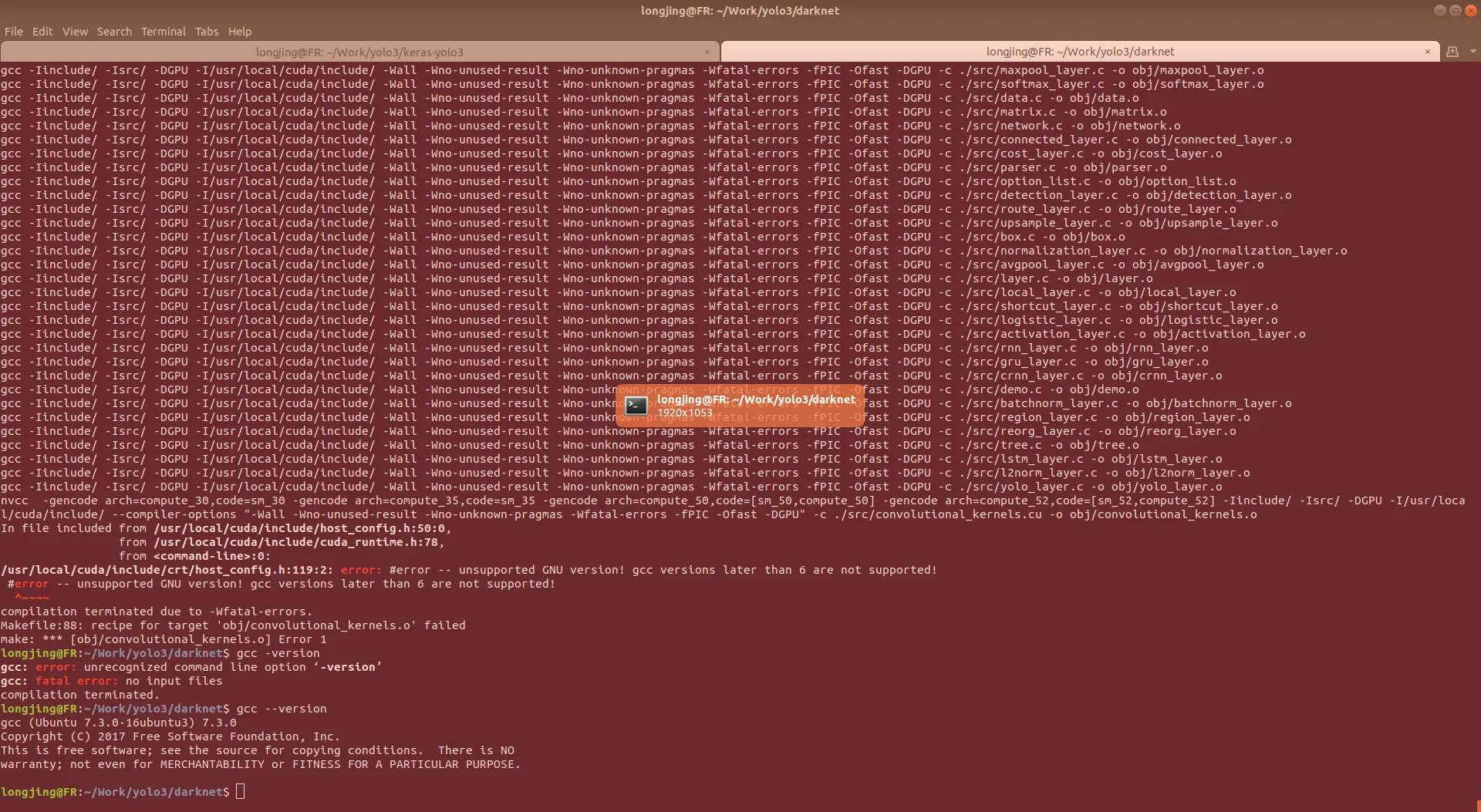
解决方法如下
在 cuda 8.0中做一个 gcc-5 的一个软连接,非常方便。不建议去修改操作系统的默认gcc 版本,风险太大
sudo ln -s /usr/bin/gcc-5 /usr/local/cuda/bin/gcc关于 CUDA 的安装可以参考之前的一篇文章 ubuntu安装CUDA
同样的,如果需要 opencv 的支持,修改 Makefile,将 OPENCV=0 改成 OPENCV=1,接着也是 make
如果需要 debug, 修改 DEBUG=1, 很不幸我这里报了个错
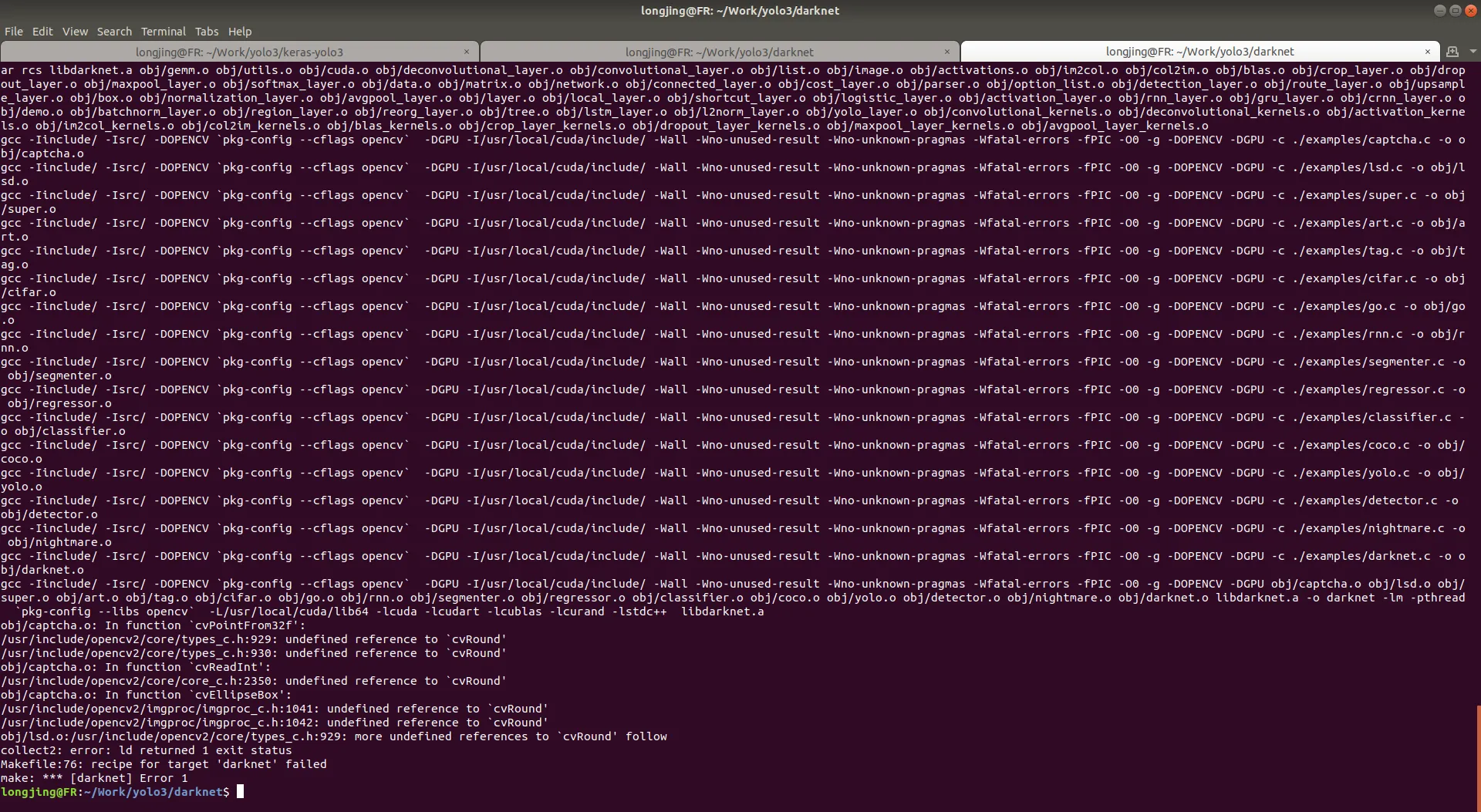
解决方法是修改 Makefile 文件,大概是35行左右(每个版本可能不太一样),将
ifeq ($(DEBUG), 1)
OPTS=-O0 -g
endif修改成
ifeq ($(DEBUG), 1)
OPTS=-O4 -g
endif这个是 GCC 编译器进行编译期优化的参数

我这编译的时候, Makefile 是这样的
GPU=1
OPENCV=1
DEBUG=1Darknet命令行工具的使用
使用之前,需要下载 yolov3 的 weights 文件,也就是模型文件, 这里给了2个链接, yolov3-tiny.weights 是 yolov3.weights 的缩小版, 根据需要自行选择
wget https://pjreddie.com/media/files/yolov3.weights
wget https://pjreddie.com/media/files/yolov3-tiny.weights检测图片中的物体
单张图片检测,执行
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg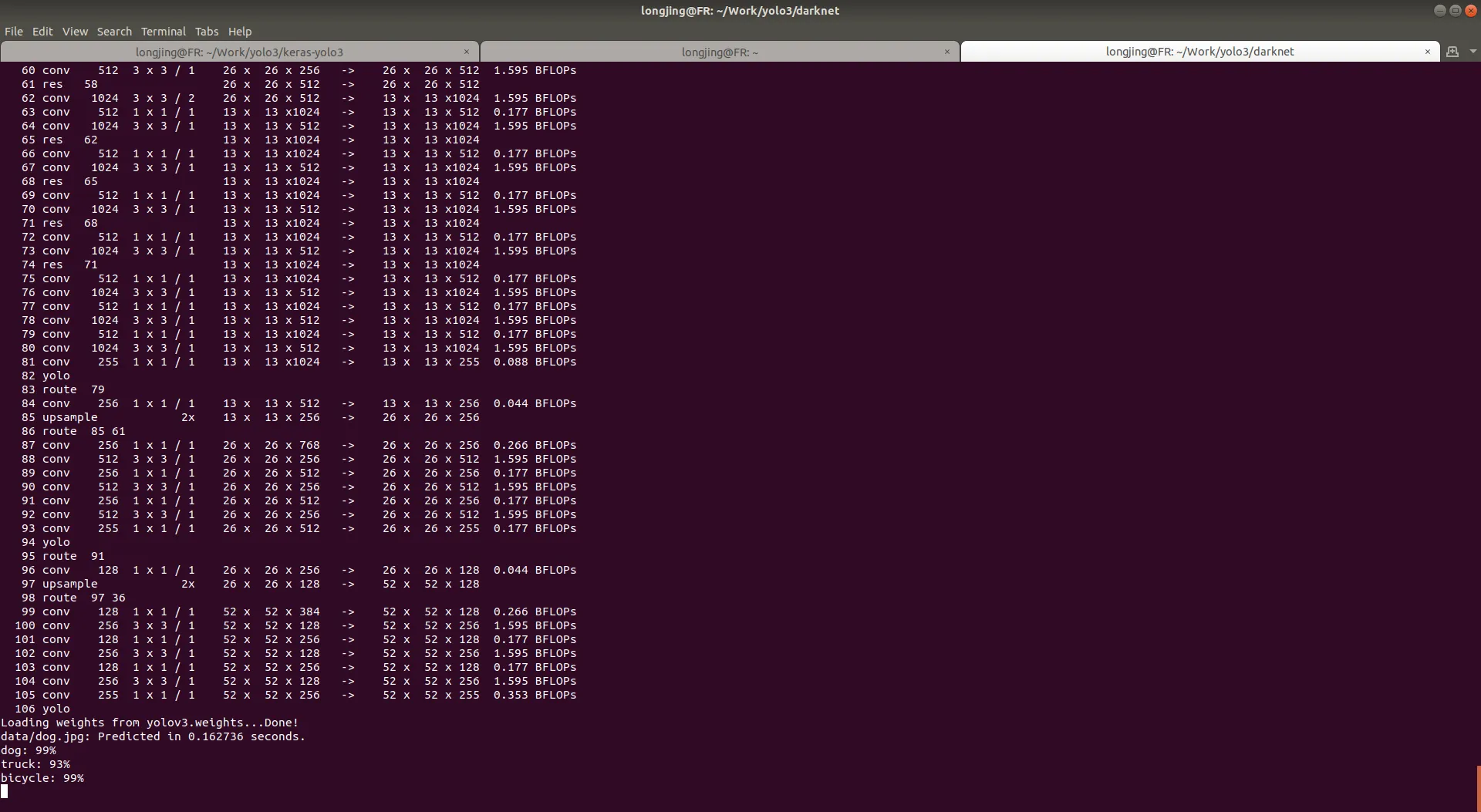
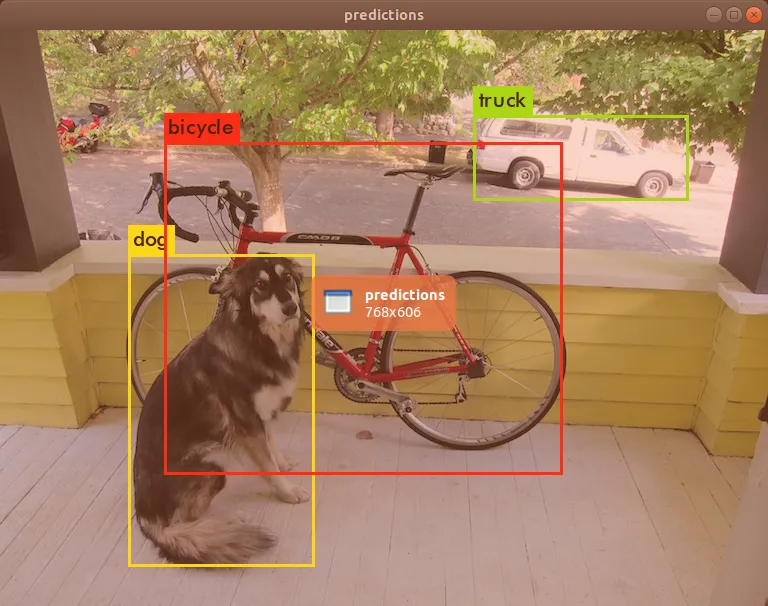
如果需要进行多张图片的连续检测,可以省略上述命令中的图片路径
使用摄像头检测物体
使用本地摄像头进行检测,执行
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights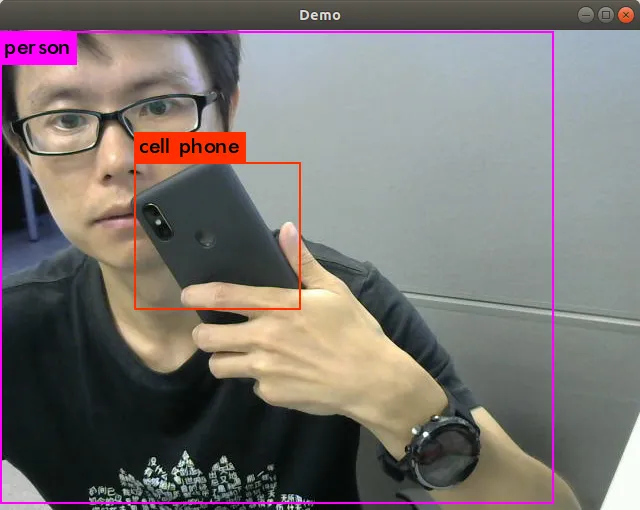
检测视频文件中的物体
使用本地视频文件进行检测,执行
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights ~/Videos/pbs5e6.mkv使用 GPU 加速的话,效果还是不错的, 简单测试了下,mp4 和 mkv 封装格式都是支持的
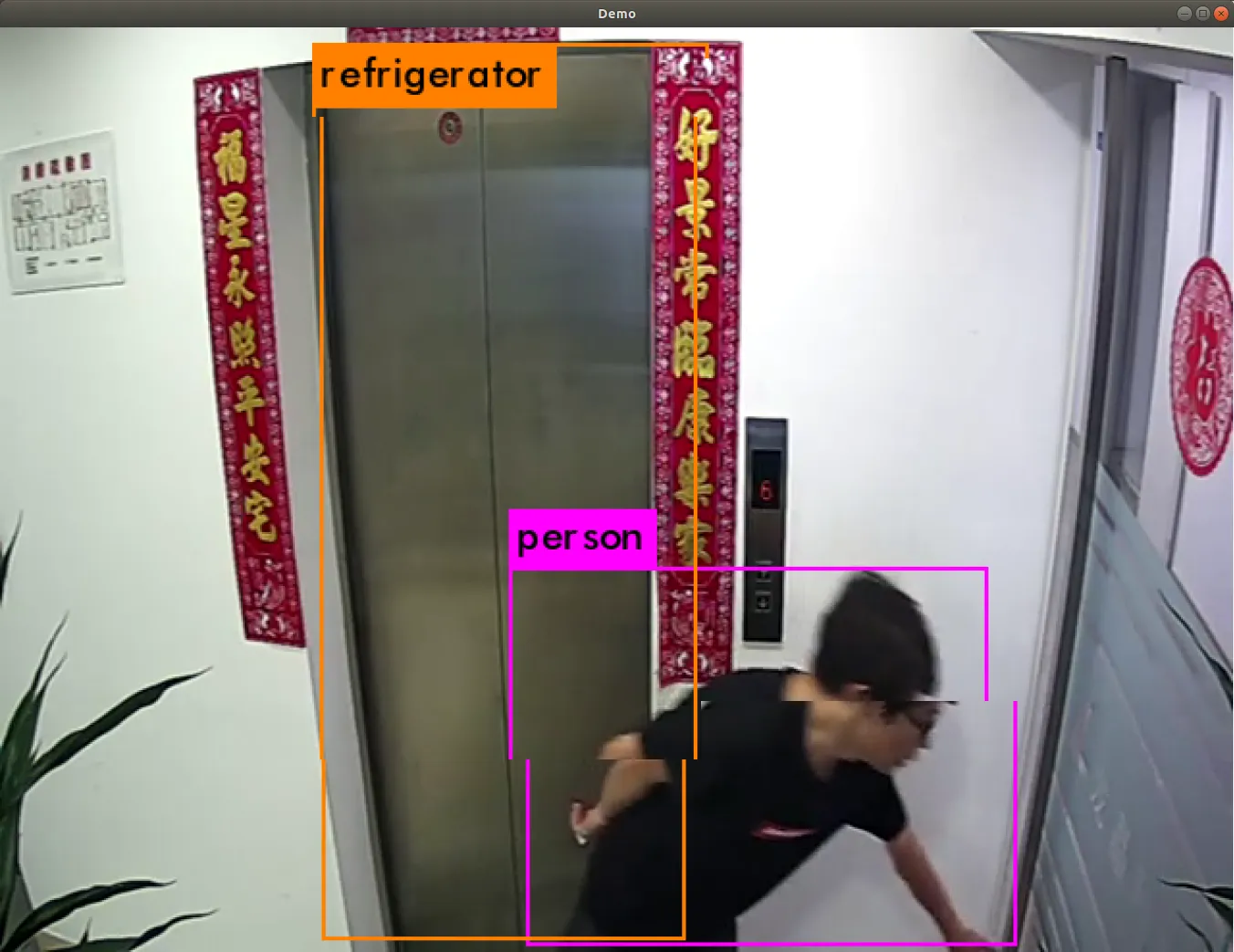
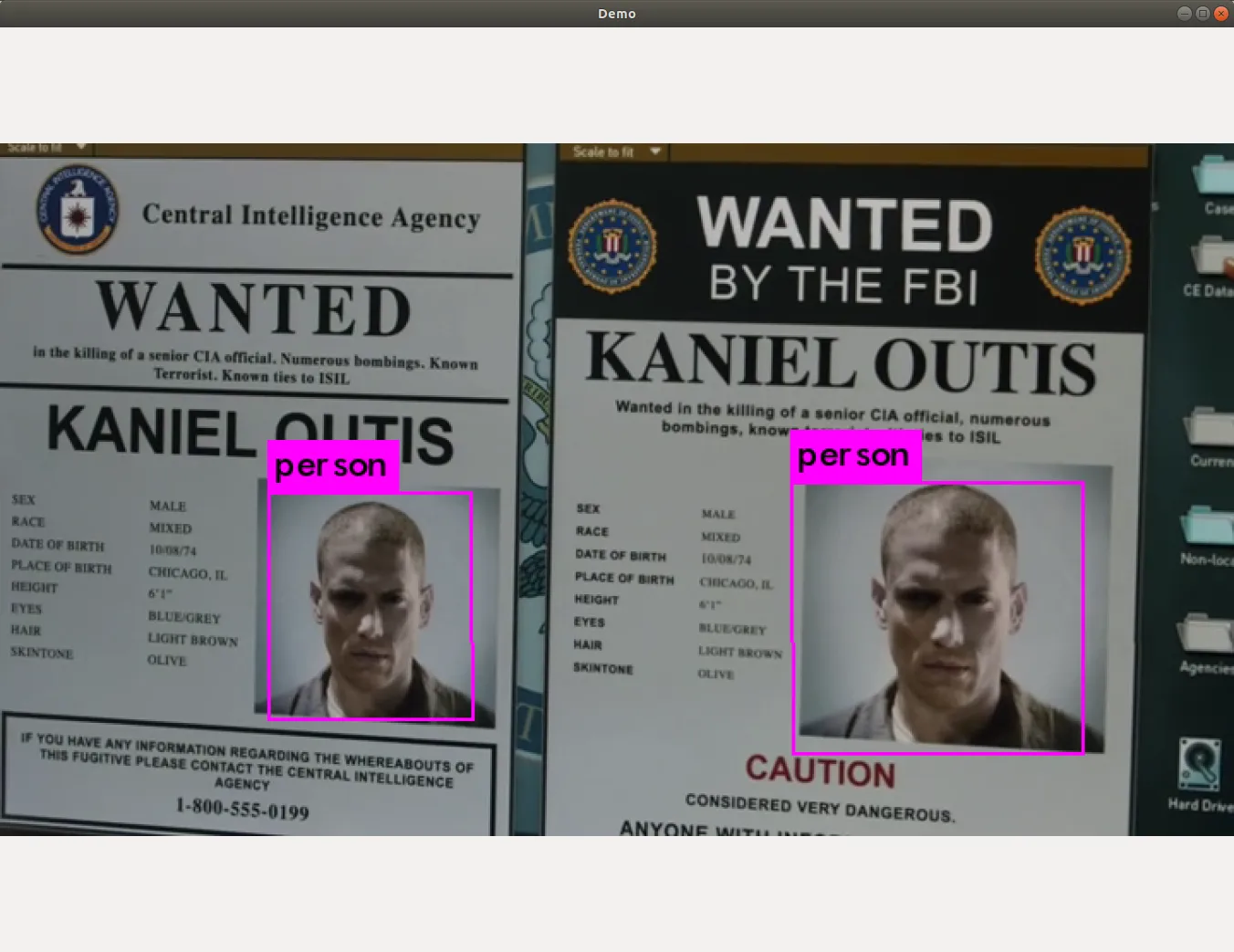
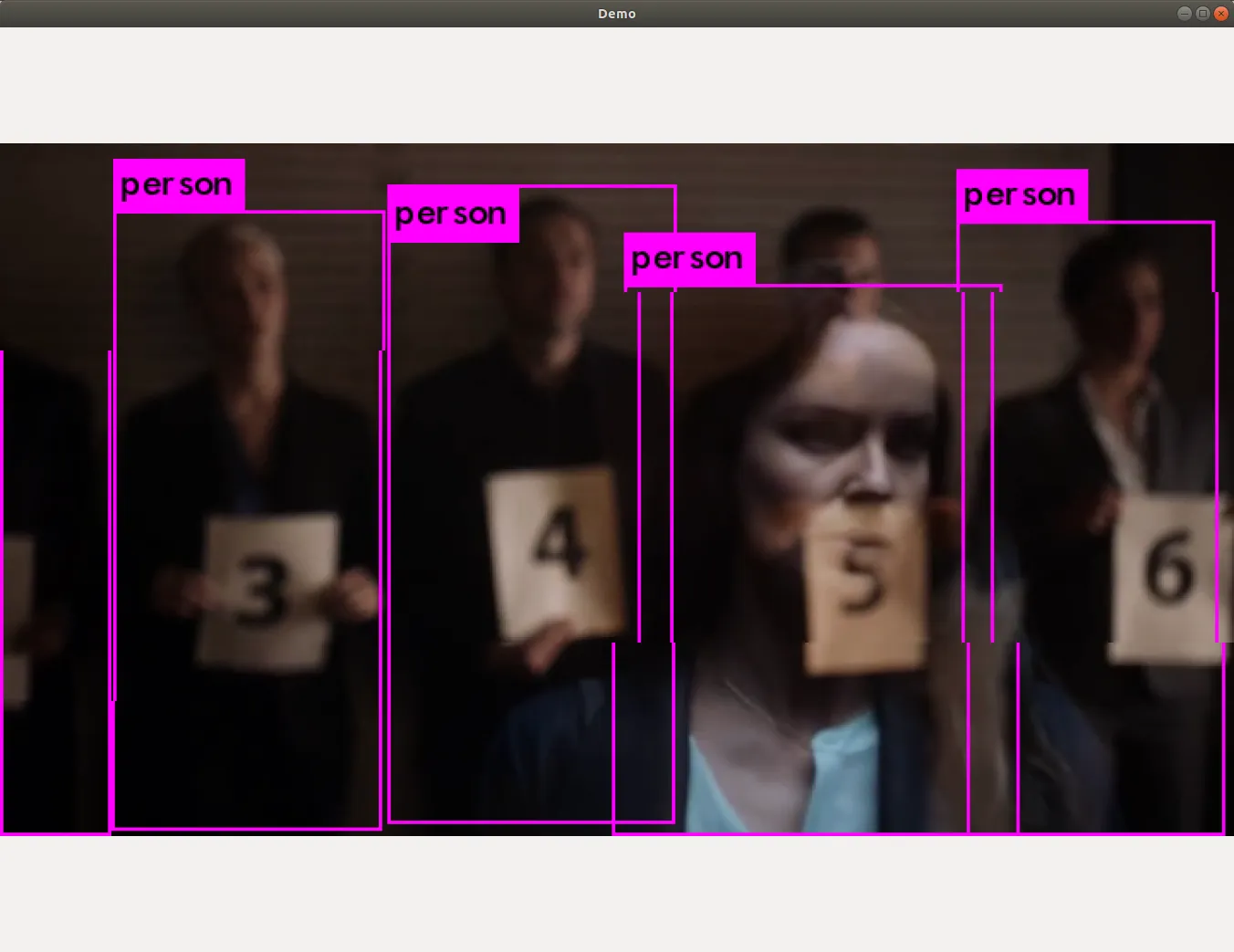
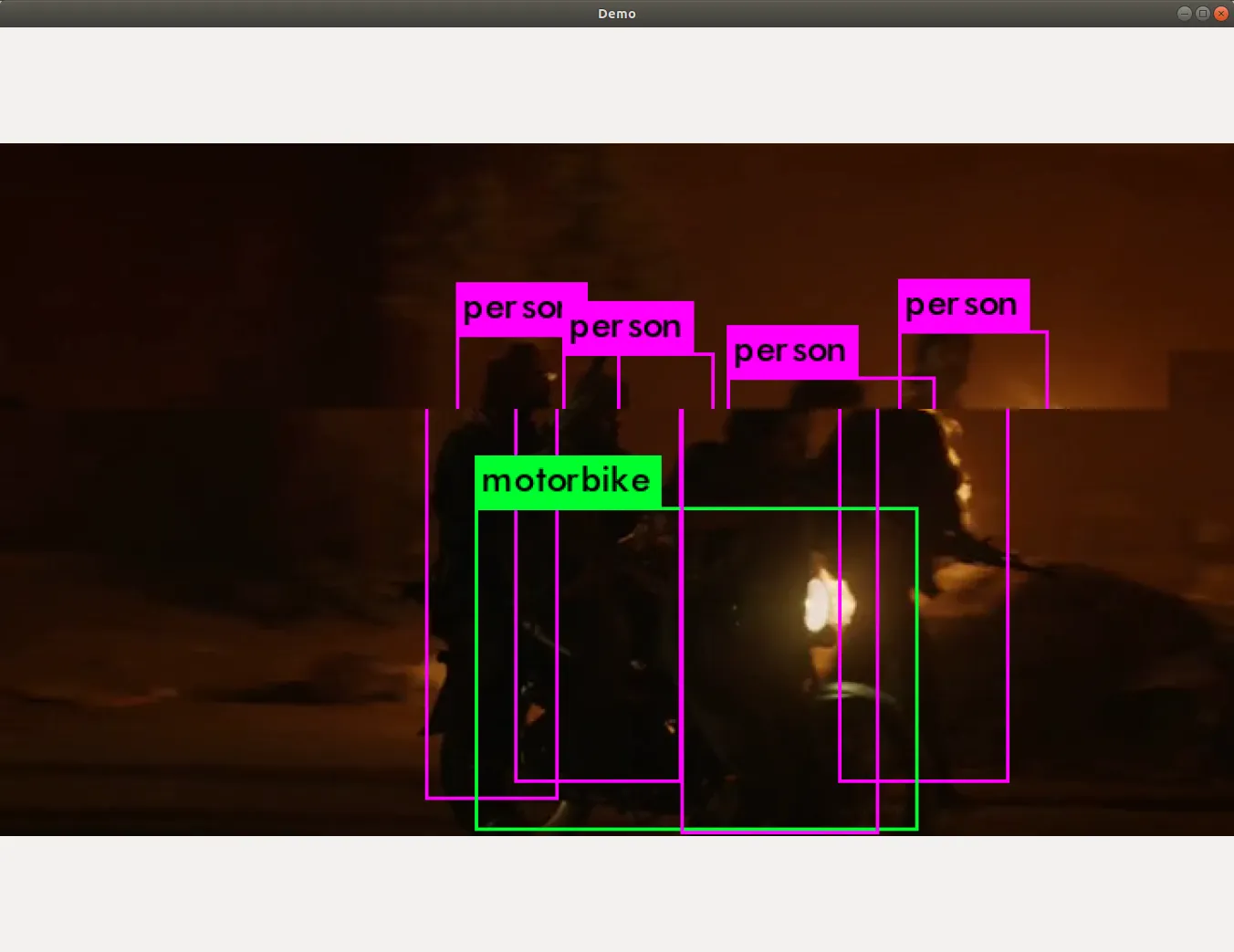

设置检测阈值
增加参数 -thresh, 默认值是0.25, 数值越高检测越严格
weights训练
这里以PASCAL VOC数据集为例,重新训练 weights 文件
准备数据集
官方提供了下载链接,分别执行下面命令
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar生成label文件
首先我们需要生成 darknet 使用的 label 文件, 这是一个 txt 文件, 内容如下, 是跟图片宽度和高度相关的一组数据。
<object-class> <x> <y> <width> <height>官方已经有了一个转换的脚步, 我们拉取下来直接用
wget https://pjreddie.com/media/files/voc_label.py
python voc_label.py执行完后, 在目录 VOCdevkit/VOC2007/labels 和 VOCdevkit/VOC2012/labels 下产生很多的 label 文件, 数据集中有多少图片就对应有多少 label 文件, 而在 darknet 根目录同时也生成了几个 txt 文件, 如下
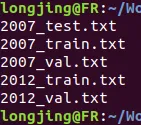
一般来讲, 在进行数据集的训练时都会准备3份数据, 一份用作训练 train, 一份用作验证 val, 最后一份用来测试 test, 这些文件仅仅指明了相应图片的路径. 这里把2007年的 test 保留, 其余的都拿来训练, 理论上讲, 训练数据越大, 效果越好, 这里的 VOC 数据集大概有15000+张图片
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt编辑VOC数据集的配置文件
配置文件路径是 cfg/voc.data, 主要是修改几个 txt 文件的路径, 如果需要增减 class 种类, 这里的 classes 也是需要修改的
classes= 20
train = /home/longjing/Work/yolo3/darknet/train.txt
valid = /home/longjing/Work/yolo3/darknet/2007_test.txt
names = data/voc.names
backup = backup下载官方训练好的卷积层weights
在训练 VOC 的时候需要用到它,执行
wget https://pjreddie.com/media/files/darknet53.conv.74开始训练
修改 cfg/yolov3-voc.cfg, 训练和测试采用不用的参数,不同显卡的算力不同,这里也要做相应的值修改
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=16然后执行训练命令
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74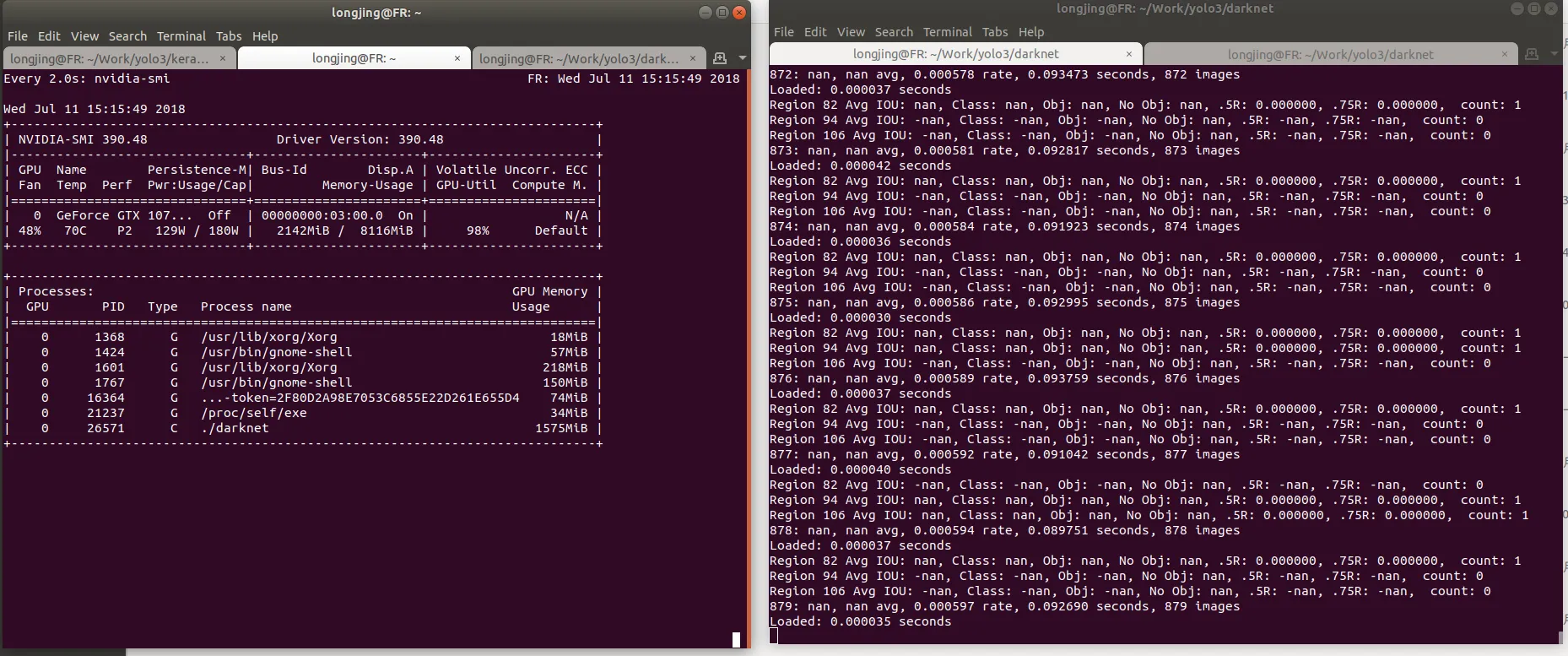
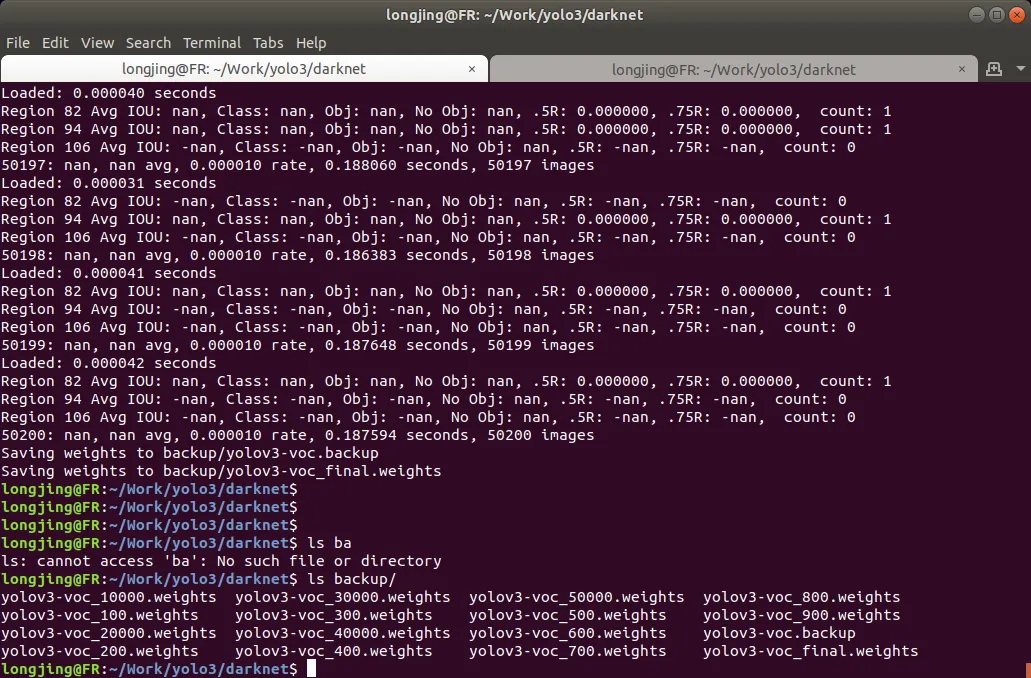
训练结束后,weights 文件成功生成, 在 backup 目录下
参考资料
- https://pjreddie.com/darknet/install/
- https://stackoverflow.com/questions/6622454/cuda-incompatible-with-my-gcc-version
- https://www.youtube.com/watch?v=KD8fT49KXv8
- https://groups.google.com/forum/#!topic/darknet/fQ2GQuibBA4
- https://github.com/pjreddie/darknet/issues/492
- https://pjreddie.com/darknet/yolo/
- https://pjreddie.com/media/files/papers/YOLOv3.pdf

