环境
- windows 10 64bit
- AudioLDM 0.1.1
- anaconda with python 3.8
- nvidia gtx 1070Ti
简介
AudioLDM 是一个开源的音频处理库,它可以用于实现语音识别、语音合成、语音转换等应用。该库提供了一组音频信号处理算法,包括语音信号的预处理、特征提取、噪声抑制、语音增强、声学模型训练等。
项目开源地址:https://github.com/haoheliu/AudioLDM
截止到目前(20230505),AudioLDM 的几大核心功能
- 文本到音频(
Text-to-Audio):给予文本输入,生成音频 - 音频到音频(
Audio-to-Audio):给定一个音频,生成另一个包含相同类型声音的音频 - 文本指导的音频到音频的风格转换(
Text-guided Audio-to-Audio Style Transfer):使用文本描述将一个音频的声音转移到另一个音频中
实操
首先,使用 conda 创建一个全新的 python 虚拟环境
conda create -n audioldm python=3.8
conda activate audioldm库的安装可以直接使用 pip
pip install audioldm使用之前,我们先准备好模型,其实在命令处理的时候,会自动去下载,但是由于网络和文件太大的问题,经常导致失败。
这里提供了一份,供大家下载
链接:https://pan.quark.cn/s/51ad4c52bd5f
解压后,将文件夹 audioldm 放到 C:\Users\$你的用户名\.cache 下面,没有的文件夹,自己创建
链接:https://pan.quark.cn/s/b85444078028
解压后,同样也是将文件夹 huggingface 放到 C:\Users\$你的用户名\.cache 下面
完成后,就可以直接使用命令行工具 audioldm 来体验体验了
# 根据文本来生成
audioldm -t "A hammer is hitting a wooden surface" # 根据声音生成
audioldm --file_path trumpet.wav# 声音风格迁移
audioldm --mode "transfer" --file_path trumpet.wav -t "Children Singing" 如果在跑上述命令时出现类似下面的报错
Load AudioLDM: %s audioldm-m-full
DiffusionWrapper has 415.95 M params.
C:\Users\xgx\anaconda3\envs\audioldm\lib\site-packages\torchlibrosa\stft.py:193: FutureWarning: Pass size=1024 as keyword args. From version 0.10 passing these as positional arguments will result in an error
fft_window = librosa.util.pad_center(fft_window, n_fft)
C:\Users\xgx\anaconda3\envs\audioldm\lib\site-packages\torch\functional.py:504: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\TensorShape.cpp:3484.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
Some weights of the model checkpoint at roberta-base were not used when initializing RobertaModel: ['lm_head.dense.bias', 'lm_head.decoder.weight', 'lm_head.bias', 'lm_head.dense.weight', 'lm_head.layer_norm.weight', 'lm_head.layer_norm.bias']
- This IS expected if you are initializing RobertaModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RobertaModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Traceback (most recent call last):
File "C:\Users\xgx\anaconda3\envs\audioldm\lib\runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Users\xgx\anaconda3\envs\audioldm\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "C:\Users\xgx\anaconda3\envs\audioldm\lib\site-packages\audioldm\__main__.py", line 152, in <module>
audioldm = build_model(model_name=args.model_name)
File "C:\Users\xgx\anaconda3\envs\audioldm\lib\site-packages\audioldm\pipeline.py", line 89, in build_model
latent_diffusion = latent_diffusion.to(device)
File "C:\Users\xgx\anaconda3\envs\audioldm\lib\site-packages\torch\nn\modules\module.py", line 1145, in to
return self._apply(convert)
File "C:\Users\xgx\anaconda3\envs\audioldm\lib\site-packages\torch\nn\modules\module.py", line 797, in _apply
module._apply(fn)
File "C:\Users\xgx\anaconda3\envs\audioldm\lib\site-packages\torch\nn\modules\module.py", line 844, in _apply
self._buffers[key] = fn(buf)
File "C:\Users\xgx\anaconda3\envs\audioldm\lib\site-packages\torch\nn\modules\module.py", line 1143, in convert
return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 8.00 GiB total capacity; 7.30 GiB already allocated; 0 bytes free; 7.36 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF这是由于显卡的显存小了,我这里测试了,8G 是跑不了默认的模型,也就是 audioldm-full-l.ckpt。因此,可以更换更小的模型,通过参数 --model_name 来指定
audioldm --model_name audioldm-s-full-v2 -t "A hammer is hitting a wooden surface"除了可以使用命令行来处理声音,源码中还集成了 (gradio)[https://xugaoxiang.com/2023/04/27/python-web-gradio/] 这个 web 框架,方便大家在网页中操作
git clone https://github.com/haoheliu/AudioLDM
cd AudioLDM
python app.py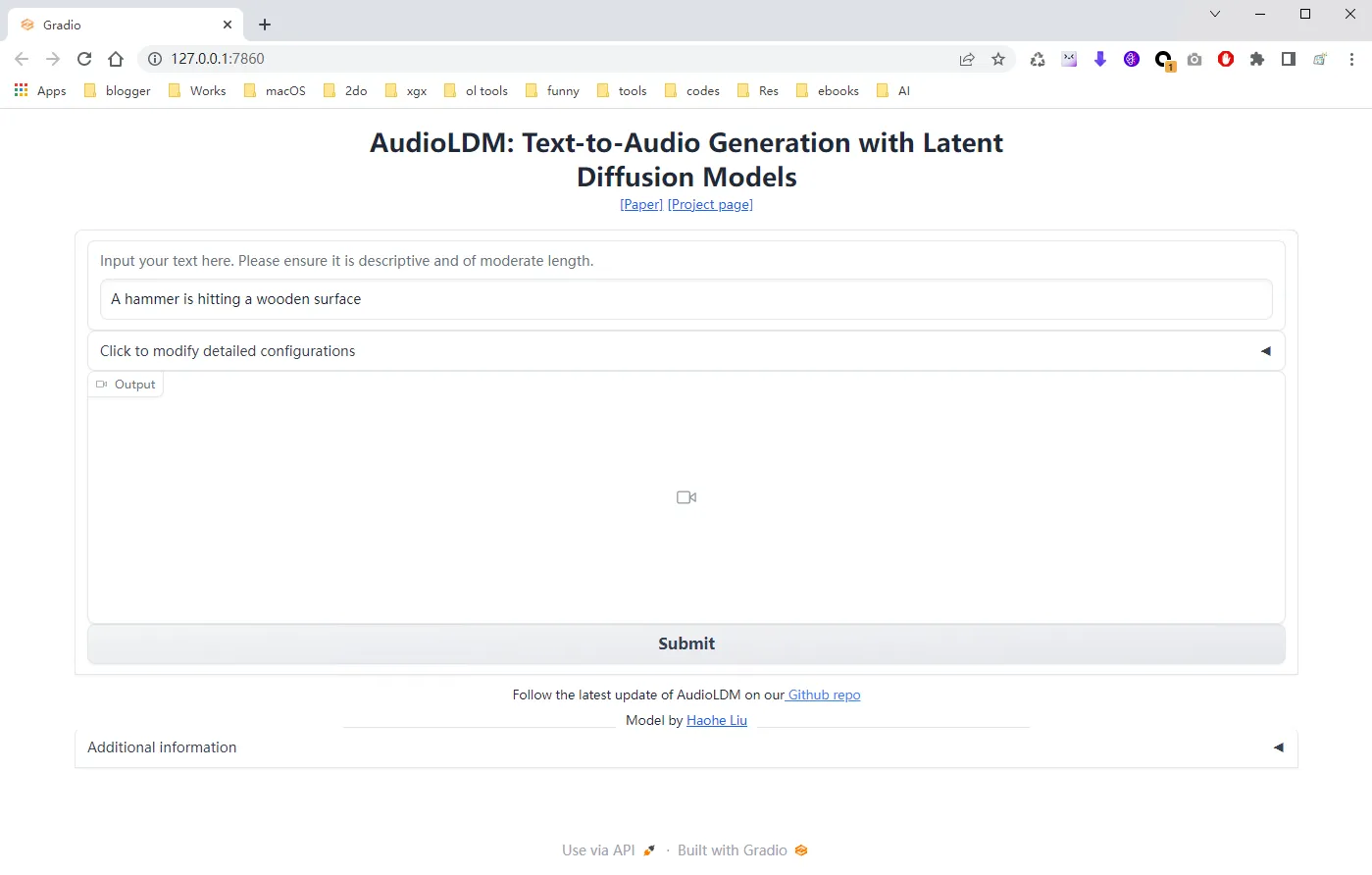
对于不懂技术的同学来讲,这个还是非常友好的。
备注
关于中文的使用问题,测试了,发现效果很差。可以来个曲线救国,就是使用翻译软件将中文翻成英文,然后使用。这里推荐一个 chrome 浏览器的插件 deepl,非常好用,插件地址:https://chrome.google.com/webstore/detail/deepl-translate-reading-w/cofdbpoegempjloogbagkncekinflcnj?utm_source=chrome-ntp-icon
FAQ
Traceback (most recent call last):
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\urllib3\connectionpool.py", line 700, in urlopen
self._prepare_proxy(conn)
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\urllib3\connectionpool.py", line 994, in _prepare_proxy
conn.connect()
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\urllib3\connection.py", line 364, in connect
conn = self._connect_tls_proxy(hostname, conn)
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\urllib3\connection.py", line 501, in _connect_tls_proxy
socket = ssl_wrap_socket(
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\urllib3\util\ssl_.py", line 453, in ssl_wrap_socket
ssl_sock = _ssl_wrap_socket_impl(sock, context, tls_in_tls)
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\urllib3\util\ssl_.py", line 495, in _ssl_wrap_socket_impl
return ssl_context.wrap_socket(sock)
File "D:\Tools\anaconda3\envs\tf\lib\ssl.py", line 500, in wrap_socket
return self.sslsocket_class._create(
File "D:\Tools\anaconda3\envs\tf\lib\ssl.py", line 1040, in _create
self.do_handshake()
File "D:\Tools\anaconda3\envs\tf\lib\ssl.py", line 1309, in do_handshake
self._sslobj.do_handshake()
ssl.SSLEOFError: EOF occurred in violation of protocol (_ssl.c:1131)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\requests\adapters.py", line 440, in send
resp = conn.urlopen(
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\urllib3\connectionpool.py", line 785, in urlopen
retries = retries.increment(
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\urllib3\util\retry.py", line 592, in increment
raise MaxRetryError(_pool, url, error or ResponseError(cause))
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /roberta-base/resolve/main/vocab.json (Caused by SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:1131)')))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\Tools\anaconda3\envs\tf\lib\runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "D:\Tools\anaconda3\envs\tf\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\audioldm\__main__.py", line 152, in <module>
audioldm = build_model(model_name=args.model_name)
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\audioldm\pipeline.py", line 81, in build_model
latent_diffusion = LatentDiffusion(**config["model"]["params"])
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\audioldm\ldm.py", line 66, in __init__
self.instantiate_cond_stage(cond_stage_config)
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\audioldm\ldm.py", line 125, in instantiate_cond_stage
model = instantiate_from_config(config)
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\audioldm\utils.py", line 97, in instantiate_from_config
return get_obj_from_str(config["target"])(**config.get("params", dict()))
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\audioldm\utils.py", line 87, in get_obj_from_str
return getattr(importlib.import_module(module, package=None), cls)
File "D:\Tools\anaconda3\envs\tf\lib\importlib\__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1014, in _gcd_import
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 843, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\audioldm\clap\encoders.py", line 4, in <module>
from audioldm.clap.training.data import get_audio_features
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\audioldm\clap\training\data.py", line 58, in <module>
tokenize = RobertaTokenizer.from_pretrained("roberta-base")
ined
resolved_vocab_files[file_id] = cached_file(
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\transformers\utils\hub.py", line 409, in cached_file
resolved_file = hf_hub_download(
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\huggingface_hub\utils\_validators.py", line 120, in _inner_fn
return fn(*args, **kwargs)
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\huggingface_hub\file_download.py", line 1181, in hf_hub_download
metadata = get_hf_file_metadata(
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\huggingface_hub\utils\_validators.py", line 120, in _inner_fn
return fn(*args, **kwargs)
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\huggingface_hub\file_download.py", line 1513, in get_hf_file_metadata
r = _request_wrapper(
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\huggingface_hub\file_download.py", line 407, in _request_wrapper
response = _request_wrapper(
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\huggingface_hub\file_download.py", line 442, in _request_wrapper
return http_backoff(
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\huggingface_hub\utils\_http.py", line 212, in http_backoff
response = session.request(method=method, url=url, **kwargs)
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\requests\sessions.py", line 529, in request
resp = self.send(prep, **send_kwargs)
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\requests\sessions.py", line 645, in send
r = adapter.send(request, **kwargs)
File "D:\Tools\anaconda3\envs\tf\lib\site-packages\requests\adapters.py", line 517, in send
raise SSLError(e, request=request)
requests.exceptions.SSLError: HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /roberta-base/resolve/main/vocab.json (Caused by SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:1131)')))解决方法是,降低 urllib3 的版本号
pip install urllib3==1.25.11


